为什么 SQL 语句使用了索引,但却还是慢查询?
一、索引与慢查询
聊一聊索引和慢查询,经常遇到的一个问题:一个SQL语句使用了索引,为什么还是会记录到慢查询日志之中?
为了说明,创建一个表t,该表3个字段,一个主键索引,一个普通索引
CREATE TABLE `t` (
`id` int(11) NOT NULL,
`a` int(11) DEFAULT NULL,
`b` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `a` (`a`)
) ENGINE=InnoDB;
insert into t values (1, 1, 1), (2, 2, 2);首先MySQL判断一个语句是不是慢查询语句,用的是语句执行时间,它把语句执行时间跟long_query_time这个系统参数做比较,如果语句执行时间比long_query_time还大,就会把这个语句记录到慢查询日志里。
long_query_time这个参数它的默认值是10s,在生产上我们不会设置这么大的值,一般会设置1s,对于一些对延迟比较敏感的业务,会设置一个比1还小的值,而对于语句是否使用了索引,它的意思是语句执行过程中有没有用到表的索引。
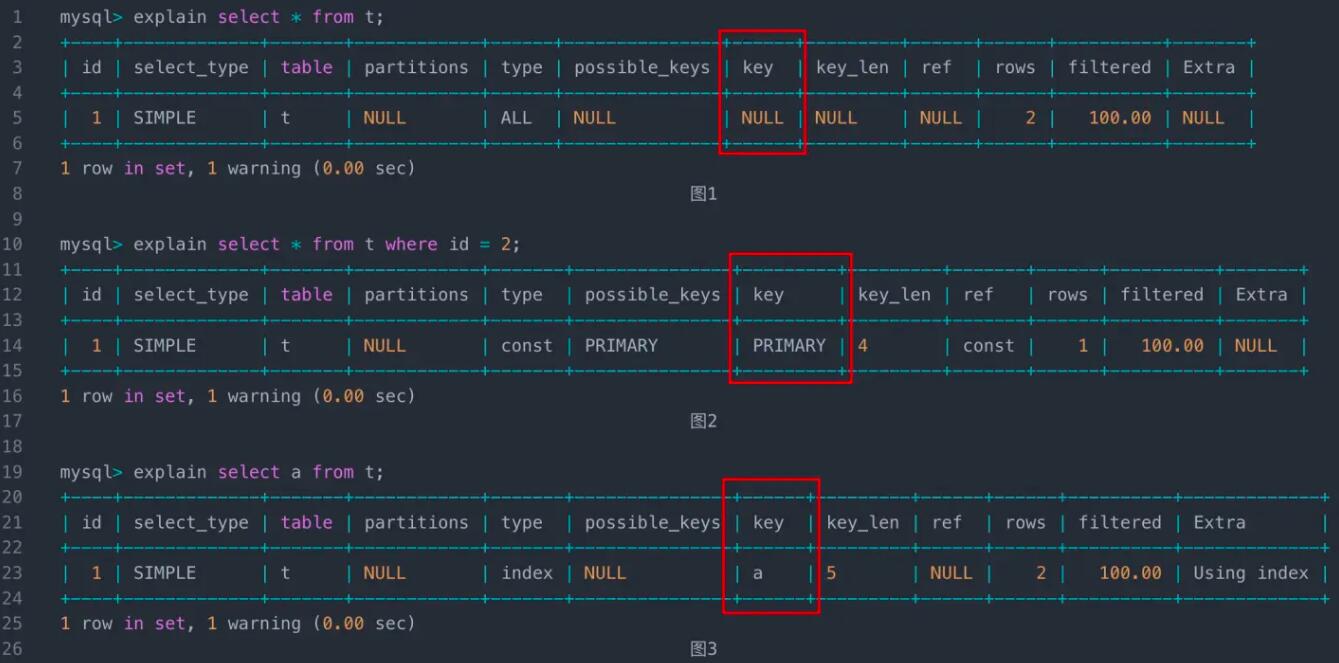
具体到表象中是explain一个语句的时候,输出结果里面key的值不是NULL,图1就是执行 explain select * from t; 的结果。可以看到key这一列显示的是NULL。图2就是执行explain select * from t where id = 2的结果,这里key显示的是PRIMARY,就是我们常说的使用了主键索引。图3就是执行select a from t 的结果,这里key这一列显示的是a,表示使用了a这个索引。可以看到图2和图3的结果里key的字段都不是NULL,而实际上图3是扫描了整个索引树a。
这个示例的表里面只有两行,那如果有100万行呢,有100万行的时候图2的语句还是可以执行很快,但是图3就肯定慢了,如果是更极端的情况,比如如果这个数据库上CPU压力非常地高,那可能第二个语句的执行时间也会超过long_query_time,会记录到慢查询日志里面,所以如果简单地回答这个问题,是否使用索引只是表示了一个SQL语句的执行过程,而是否记录到慢查询日志中是由它的执行时间决定的,而这个执行时间可能会受各种外部因素的影响,也就是说 是否使用索引和是否记录慢查询之间没有必然的联系 。
二、索引的过滤性
如果我们再深层次的看这个问题其实它还潜藏着一个问题需要澄清就是,什么叫做使用了索引。我们知道InnoDB是索引组织表,所有的数据都是存储在索引树上面的,比如表t,这个表它包含了两个索引,一个主键索引一个普通索引a,在InnoDB里数据是放在主键索引里的。我们来看一下这个表的数据示意图,可以看到数据都放在主键索引上,如果从逻辑上说,所有的在InnoDB表上的查询,都至少用了一个索引,现在有一个问题:如果执行explain select * from t where id > 0; 这个语句有用上索引吗?
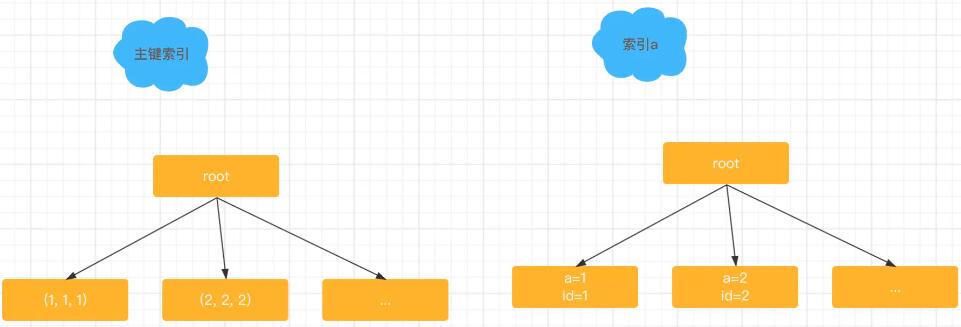

现在我们来看看这个语句的explain的结果,在输出结果里,key这里显示的是PRIMARY,其实从数据上你是知道的这个语句一定是做了全表扫描,但是优化器认为,这个语句的执行过程中,需要根据主键索引定位到第一个满足id>0的值,也算用到了索引。所以你看,即使explain结果里面写了key不是NULL,实际上也可能是全表扫描的,因此InnoDB里面只有一种情况叫做没有使用索引,那就是从主键索引的最左边的叶节点开始,向右扫描整个索引树,也就是说,没有使用索引并不是一个准确的描述,你可以用 全表扫描 来表示一个查询遍历了整个主键索引树。也可以用全索引扫描来说明,像select a from t这样的查询,它扫描了整个普通索引树。而像select * from t where id = 2; 这样的语句才是我们平时说的使用了索引,它表示的意思是我们使用了索引的快速搜索功能,并且有效的减少了扫描行数。
那么除了全索引扫描,还有哪些是使用了索引但是执行速度不够快的例子呢,这就要说到 索引的过滤性 ,假设你现在维护了一个表,这个表记录了全中国人的基本信息,然后你现在要查出年龄在10到15岁之间的小朋友的姓名和基本信息,那么你的语句会这么写,select * from t_people where age between 10 and 15;你一看这个语句一定要在age字段上建索引了,否则就是个全表扫描。但是你会发现在age上建了索引以后,这个语句还是执行慢,因为满足这个条件的数据有超过1亿行。我们来看看建立了这个索引以后这个表的组织结构图,这个语句的执行流程是这样的。从索引age上用树搜索,取到第一个age等于10的记录,得到它的主键ID的值,根据ID的值去主键索引取整行的信息,作为结果集的一部分返回,在索引age上向右扫描,取下一个ID值,到主键索引上取整行信息,作为结果集的一部分返回,重复上面的步骤直到碰到第一个age>15的记录。你看这个语句,虽然它用了索引,但是它扫描超过了一亿行,而上面select * from t;这个语句虽然没有用索引,但其实也只扫描了两行。
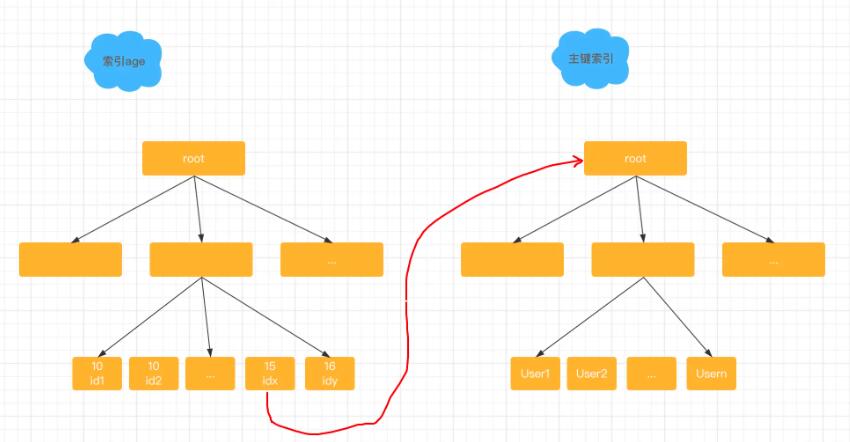
所以你现在知道了,当我们讨论有没有使用索引的时候,其实我们关心的是扫描行数,对于一个大表,不止要有索引,索引的过滤性还要足够好,像刚才这个例子age这个索引它的过滤性就不够好。在设计表结构的时候,我们要让索引的过滤性足够好,也就是区分度足够高。那么过滤性好了,是不是表示查询的扫描行数就一定少呢,我们再来看一个例子。
三、索引的扫描行数

如果这个t_people表上有一个索引是姓名、年龄的联合索引,那这个联合索引的过滤性应该不错,如果你的执行语句是select * from t_people where name = '张三' and age = 8; 就可以在一个索引上快速找到第一个姓名是张三并且年龄是8岁的小朋友,当然这样的小朋友就该不多,因此向右扫描的行数很少,查询效率就很高,但是查询的过滤性和索引的过滤性可并不一定是一样的。如果现在你的需求是查出所有名字第一个字是张并且年龄是8岁的所有小朋友,你的语句会怎么写呢?你的语句要这么写:select * from t_people where name like '张%' and age = 8; 在MySQL5.5和之前的版本中,这个语句的执行流程是这样的。首先从联合索引树上找到第一个姓名字段是张开头的记录,取出主键ID,然后到主键索引上,根据ID取出整行的值,判断年龄字段是否等于8如果是就作为结果集的一行返回,如果不是就丢弃,我们把根据ID到主键索引上查找整行数据这个动作称为 回表 ,在联合索引上向右遍历,并重复做回表和判断的逻辑直到碰到联合索引树上名字第一个字不是张的记录为止。你可以看到这个执行过程里面最耗费时间的步骤就是回表,假设全国名字第一个字是张的人有8000万,那么这个过程就要回表8000万次,在定位第一行记录的时候,只能使用索引和联合索引的最左前缀,称为最左前缀原则。那你可以看到这个执行过程它的回表次数特别多,性能不够好,那有没有优化的方法呢?有的在MySQL5.6版本引入了index condition pushdown的优化,我们来看看这个优化的执行流程。
首先从联合索引树上找到第一个姓名字段是张开头的记录,判断这个索引记录里面年龄的值是不是8,如果是就回表,取出整行数据作为结果集的一部分返回,如果不是就丢弃。在联合索引树上向右遍历,并判断年龄字段后根据需要做回表,直到碰到联合索引树上名字的第一个字不是张的记录为止。这个过程跟上面过程的差别是在遍历联合索引的过程中,将年龄等于8这个条件下推到索引遍历的过程中,减少了回表的次数,假设全国名字第一个字是张的人里面朋100万个是8岁的小朋友,那么这个查询过程中,在联合索引里要遍历8000万次,而回表只需要100万次。可以看到,index condition pushdown 优化的效果还是很不错的,但是这个优化,还是没有绕开最左前缀原则的限制,因此在联合索引里,还是要扫描8000万行,那有没有更进一下的优化方法呢?我们可以把名字的第一个字,和年龄做一个联合索引来试试,这里可以用到MySQL 5.7引入的虚拟列来实现,对应的修改表结构的SQL语句是这么写的。
alter table t_people add name_first varchar(2) generated always as
(left(name, 1)), add index (name_first, age);
CREATE TABLE `t_people` (
`id` int(11) DEFAULT NULL,
`name` varchar(20) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
`info` varchar(255) DEFAULT NULL,
`name_first` varchar(2) GENERATED ALWAYS AS (left(`name`, 1)) VIRTUAL,
KEY `name_first` (`name_first`, `age`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;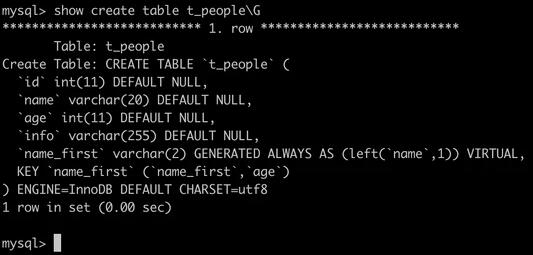
上图是这个DDL语句的执行效果,首先它在t_people上创建一个字段叫name_first虚拟列,然后给name_first和age上创建一个联合索引,并且让这个虚拟列的值,总是等于name字段的前两个字节,虚拟列在插入数据的时候,不能指定值,在更新的时候也不能指定修改,它的值会根据定义自动生成,在name字段修改的时候,也会自动修改,有了这个新的联合索引,我们再找名字第一个字是张并且年龄是8的小朋友的时候,这个SQL语句就可以这么写:select * from t_people where name_fist = '张' and age = 8; 这样这个语句的执行过程,就只需要扫描联合索引的100万行并回表100万次。这个优化的本质是创建了一个更紧凑的索引来加速了查询的过程。
四、小结
今天介绍了索引的基本结构和一些查询优化的基本思路,现在我们知道了:
1、使用索引和慢查询没有必然联系,使用索引的SQL也有可能是慢查询语句;
2、检查一个查询语句的执行效率最终要看的是扫描行数,我们查询优化的过程往往就是减少扫描行数的过程;
3、使用虚拟列和联合索引来提升复杂查询的执行效率。
来自:https://www.cnblogs.com/okokabcd/p/16359004.html
本文内容仅供个人学习、研究或参考使用,不构成任何形式的决策建议、专业指导或法律依据。未经授权,禁止任何单位或个人以商业售卖、虚假宣传、侵权传播等非学习研究目的使用本文内容。如需分享或转载,请保留原文来源信息,不得篡改、删减内容或侵犯相关权益。感谢您的理解与支持!
