字符集和编码
字符集是什么
字符集 Charset :是一个系统支持的所有字符的集合,包括各国家文字、标点符号、图形符号、数字等。——看的是不是想打人
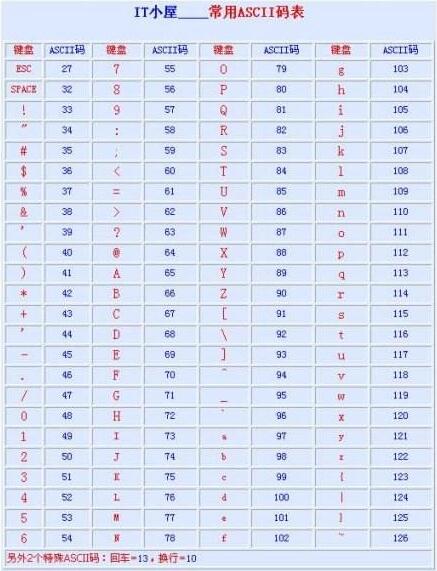
举个栗子,现在这张表你把红色的盖住,只看蓝色的,他就是个ASCII字符集。不过现在是10进制的,真正的存储到电脑中是要转成二进制的。
有的同学可能要问了,我只看蓝色的,全都是数字,我怎么知道你那个数字要表达的是什么意思。现在你在把盖住的红色的内容打开,他就变成了ascii码对照表。它就表示了ascii字符集与计算机二进制之间的对应关系。这种自然语言的字符与二进制数之间的对应规则叫做字符编码。
编码是什么
编码是信息从一种形式或格式转换为另一种形式的过程,也称为计算机编程语言的代码简称编码。用预先规定的方法将文字、数字或其它对象编成数码,或将信息、数据转换成规定的电脉冲信号。 --来自百度百科
解码是一种用特定方法,把数码还原成它所代表的内容或将电脉冲信号、光信号、无线电波等转换成它所代表的信息、数据等的过程。 --来自百度百科
继续上边的例子,现在ascii字符集与计算机语言之间的对应关系已经存在了。计算机中把从其他字符翻译成计算机中的二进制叫做编码(例如:ASCII码对照表中,a对应的是73,人类输入a,保存到计算机中,被翻译成了二进制的97,这个过程叫编码)。
反过来计算机保存的"0110 0001"也就是十进制的97,显示在你的显示屏幕上的时候是根据ASCII码对照表反向翻译过的,这个过程叫解码。
如果按照A规则存储,同样按照A规则解析,那么就能显示正确的文本符号。反之,按照A规则存储,再按照B规则解析,就会导致乱码现象。(A规则可以理解成ASCII对应关系,b规则理解为utf-编码)
字符集的发展史
ASCII字符集 :
ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)是基于拉丁字母的一套电脑编码系统,用于显示现代英语,主要包括控制字符(回车键、退格、换行键等)和可显示字符(英文大小写字符、阿拉伯数字和西文符号)。 基本的ASCII字符集,使用7位(bits)表示一个字符,共128字符。ASCII的扩展字符集使用8位(bits)表示一个字符,共256字符,方便支持欧洲常用字符。
ISO-8859-1字符集:
拉丁码表,别名Latin-1,用于显示欧洲使用的语言,包括荷兰、丹麦、德语、意大利语、西班牙语等。 ISO-5559-1使用单字节编码,兼容ASCII编码。
GBxxx字符集:
GB就是国标的意思,是为了显示中文而设计的一套字符集。
GB2312:简体中文码表。一个小于127的字符的意义与原来相同。但两个大于127的字符连在一起时,就表示一个汉字,这样大约可以组合了包含7000多个简体汉字,此外数学符号、罗马希腊的字母、日文的假名们都编进去了,连在ASCII里本来就有的数字、标点、字母都统统重新编了两个字节长的编码,这就是常说的"全角"字符,而原来在127号以下的那些就叫"半角"字符了。
GBK:最常用的中文码表。是在GB2312标准基础上的扩展规范,使用了双字节编码方案,共收录了21003个汉字,完全兼容GB2312标准,同时支持繁体汉字以及日韩汉字等。
GB18030:最新的中文码表。收录汉字70244个,采用多字节编码,每个字可以由1个、2个或4个字节组成。支持中国国内少数民族的文字,同时支持繁体汉字以及日韩汉字等。
Unicode字符集 :
Unicode编码系统为表达任意语言的任意字符而设计,是业界的一种标准,也称为统一码、标准万国码。 它最多使用4个字节的数字来表达每个字母、符号,或者文字。有三种编码方案,UTF-8、UTF-16和UTF-32。最为常用的UTF-8编码。
1. 128个US-ASCII字符,只需一个字节编码。
2. 拉丁文等字符,需要二个字节编码。
3. 大部分常用字(含中文),使用三个字节编码。
4. 其他极少使用的Unicode辅助字符,使用四字节编码。
ASCII:简单的说就是美国发明了计算机之后,用7位(bits)表示一个字符,来表达自己语言的文字,一个字节是8位,还空了一位,最高位被置为0。然后国际商业机器公司又加入了一些扩展,比如音标什么的,这下把8位全用上了。
ISO-8859-1:欧洲其他国家用电脑的时候发现全是英语,你让我们这些母语不是英语的人怎么办,于是制定了ISO-8859-1字符集,兼容ASCII编码(比如ASCII中97表达的是是小写的a,ISO-8859-1中97依然是小写的a,ISO-8859-1没有修改ASCII原来的字符集,只是在你的基础上扩展)。
GBxxx:
GB2312:终于,计算机传到中国了。美国人发明的ascii码,只要表达大小写26个字母,加上些字符就行了,但是中国的汉字很多,无法用1字节也就是八位标识,所以当时就制定了GB2312,规定了每个字占据2bytes。由于要和ASCII兼容,那这2bytes最高位不可以为0了(否则和ASCII会有冲突)。
GBK:之前只知道中国汉字多,但是没有想到这么多啊,原来规定汉子和计算机语言对应关系的时候,漏掉了好多汉字,所以在GB2312的基础上做了个扩展。
GB18030:后来发现中国的汉字确实很多,上次的GBK依然有漏掉的汉字。那就继续加吧,不过这次扩展的时候又遇到了新的问题:2字节一共才16位,最多才能表达65535个汉字,为了不跟ASCII冲突最高位又不能用,这下最多只能规定3万多了。因此GB18030多出来的汉字使用4bytes编码。当然,为了兼容GBK,这个四字节的前两位显然不能与GBK冲突。
Unicode:统一各个国家所有文字的编码,Unicode应运而生,最多使用4个字节的数字来表达每个字符。
字符集和字符编码那点事
计算机要准确的存储和识别各种字符集符号,需要进行字符编码,一套字符集必然至少有一套字符编码。
等等,一套字符集必然至少有一套字符编码,那岂不是……
没错,每套字符集可能会有多个字符编码,就像这样
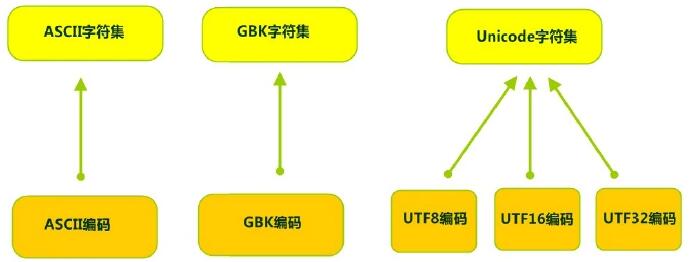
这是什么意思哪,其实也很好理解,就是字符集是固定的,比如现在有一套字符集,只有小写的26个字母。A在编写对应规则的时候把97对应a(ascii),但是B在编写的时候非要把计算机中的98对应a。这就是同样的字符集,我用不同的对应规则去翻译成计算机的语言,翻译成的计算机序言肯定不是一样的。
但是utf-8和utf-16、utf-32,并没有改变对应规则,只是改变了在计算机中的存储长度。
还记得上边说过的Unicode最多只能存四个字节吗,这就意味着,Unicode中不同的字符可以用1个、2个、3个或者4个字节保存。
UTF-16就是任何字符对应的数字都用两个字节来保存。
UTF-8时表示一个字符是可变的,有可能是用一个字节表示一个字符,也可能是两个,三个.当然最多不能超过3个字节。
UTF-32就是把所有的字符都用32bit也就是4个字节来表示。
当指定了编码,它所对应的字符集自然就指定了
本文内容仅供个人学习、研究或参考使用,不构成任何形式的决策建议、专业指导或法律依据。未经授权,禁止任何单位或个人以商业售卖、虚假宣传、侵权传播等非学习研究目的使用本文内容。如需分享或转载,请保留原文来源信息,不得篡改、删减内容或侵犯相关权益。感谢您的理解与支持!


