Puppeteer浏览器控制器_介绍Puppeteer的一些用法
Puppeteer
Puppeteer是Chrome团队开源的Node库,其提供基于DevTools协议的高阶API让开发人员能够控制Headless Chrome、Chromium、Chrome等浏览器
通过Puppeteer能够将平时手动使用浏览器的操作通过代码的方式自动化执行,例如抓取网页、填充表单、下载文件、自动化测试,甚至使用开发者工具等。
安装要求
Node v6.4.0,但建议使用v7.6.0以上,原因是Puppeteer的很多用法都是异步的,原生支持async/await显得比较友好。
npm i --save puppeteer起步
使用Puppeteer的流程比较简单,有点类似我们使用浏览器的流程,按照你操作浏览器的过程得到信息的过程,一步步执行对应的代码:
const puppeteer = require('puppeteer'); // 引用
async function open(url) {
let browser = await puppeteer.launch({
headless: true,
executablePath: '/Applications/Google Chrome Canary.app/Contents/MacOS/Google Chrome Canary'
}); // 创建browser实例,相当于打开浏览器
let page = await browser.newPage(); // 打开页面,相当于打开标签页
await page.goto(url, {
waitUnil: 'networkidle0'
}); // 跳转到指定url
/* 这里可以针对页面进行很多操作 */
browser.close(); // 关闭浏览器
}
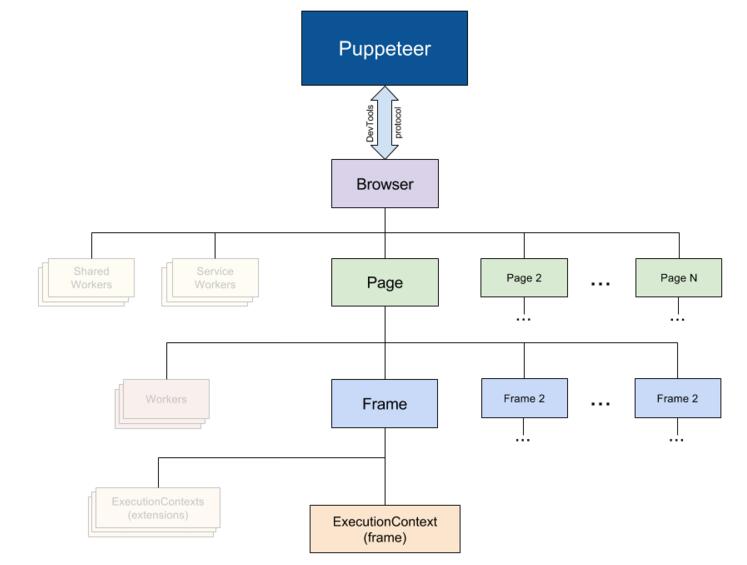
open('www.taobao.com');下图是官方结构图
Page.$(selector)
通过css selector写法获取单个对象,返回<Promise<?ElementHandle>>
Page.$$(selector)
与Page.$(selector) 类似,但返回的是一组对象,<Promise<Array<ElementHandle>>>
page.$$eval(selector, pageFunction[, ...args])
获取属性
const divsCounts = await page.$$eval('div', divs => divs.length);page.evaluate(pageFunction, ...args)
执行页面脚本
page.waitFor(selectorOrFunctionOrTimeout[, options[, ...args]])
等待指定Dom显示、等待方法执行、等待一段时间
page.waitForNavigation(options)
等待页面跳转
下文将通过几个场景来展现Puppeteer的一些用法
爬虫
抓取1688的某商品详情页内容,我们需要事先分析该页面的结构,以便能够抓取所需的信息。
| 商品名称 | dom |
| 商品信息 | 全局inline js iDetailConfig对象 |
| 商品缩略图 | 全局inline js iDetailData对象 |
| 商品详情图 | id="desc-lazyload-container" dom里面所有img,使用了lazy-load |
具体看下面的关键代码
let detailUrl = 'https://detail.1688.com/offer/564492877842.html';
/**
* 抓取详情页
* @param {Object} page
*/
async function fetchDetail(page) {
// 获取商品名称
let dTitleHandle = await page.$('.d-title'); // 使用css selector格式查找商品名称,返回
let dTitle = await page.evaluate(dTitle => dTitle.innerHTML, dTitleHandle); // 获取dom innerHTML
let iDetailConfig = await page.evaluate(x => {
return Promise.resolve(iDetailConfig);
}); // 获取页面js iDetailConfig对象
let iDetailData = await page.evaluate(x => {
return Promise.resolve(iDetailData);
}); // 获取页面js iDetailData对象
let detail = {
title: dTitle,
offerid: iDetailConfig.offerid,
skuProps: iDetailData.sku.skuProps,
skuMap: iDetailData.sku.skuMap
};
/**
* ……
*/
// 获取sku图片和缩略图
Object.keys(detail.skuMap).forEach(async (skuName) => {
let selectorStr = `tr[data-sku-config] span.image[title=${skuName}]`;
// 遍历sku信息查找对应的缩略图标签,读取data-imgs属性的json,从其中获取缩略图和原图url
let dataImgsValue = page.evaluate(selectorStr => {
return document.querySelector(selectorStr).dataset.imgs;
}, selectorStr);
let dataImgs = JSON.parse(await dataImgsValue);
// 调用第三方库下载图片
await saveImgs(dataImgs.preview, `${dir}/preview`);
await saveImgs(dataImgs.original, `${dir}/original`);
});
// 加载详情图
let preScrollHeight = 0;
let scrollHeight = -1;
while(preScrollHeight !== scrollHeight) {
// 详情信息是根据滚动异步加载,所以需要让页面滚动到屏幕最下方,通过延迟等待的方式进行多次滚动
let scrollH1 = await page.evaluate(async () => {
let h1 = document.body.scrollHeight;
window.scrollTo(0, h1);
return h1;
});
await page.waitFor(500);
let scrollH2 = await page.evaluate(async () => {
return document.body.scrollHeight;
});
let scrollResult = [scrollH1, scrollH2];
preScrollHeight = scrollResult[0];
scrollHeight = scrollResult[1];
}
let descContainerHandle = await page.$('#desc-lazyload-container');
let descImgs = await page.evaluate(descContainer => {
let descImgs = [];
descContainer.querySelectorAll('img').forEach(imgElement => {
// 遍历保存所有的详情页图片
descImgs.push({
src: imgElement.src
})
});
return descImgs;
}, descContainerHandle);
}使用Trace功能
除了基本的页面浏览功能,Puppeteer同样能够调用devtool的功能,其中就包括Trace,能够自动保存网页浏览的trace文件,能够成为分析性能的辅助工具。
async function trace(url) {
/**
* ………
*/
// 页面的trace数据会被保存到trace.json
await page.tracing.start({path: './dist/trace.json'});
await page.goto(url, {
waitUnil: 'networkidle0'
});
await page.tracing.stop();
}保存下来的json文件可以通过chrome devtool加载手动分析,也可以通过程序方式提取关键信息进行自动分析,如页面加载速度、页面展现截图、脚本执行性能等,这个功能在自动化监控方面会有很大的想象空间。
总结
Puppeteer的出现提升了开发、测试对浏览器的自动化控制能力,其性能、API友好度、兼容性都远远超过PhantomJS,对于使用者来说,需要更多地思考如何更好地利用工具的能力,例如爬虫的难点并不在于爬虫工具,而是如何更有效率地抓取数据、反爬,获取Trace后的分析同样才是技术难点。
来源:https://segmentfault.com/a/1190000013978236
本文内容仅供个人学习、研究或参考使用,不构成任何形式的决策建议、专业指导或法律依据。未经授权,禁止任何单位或个人以商业售卖、虚假宣传、侵权传播等非学习研究目的使用本文内容。如需分享或转载,请保留原文来源信息,不得篡改、删减内容或侵犯相关权益。感谢您的理解与支持!