Redis 的底层数据结构(整数集合)
当一个集合中只包含整数,并且元素的个数不是很多的话,redis 会用整数集合作为底层存储,它的一个优点就是可以节省很多内存,虽然字典结构的效率很高,但是它的实现结构相对复杂并且会分配较多的内存空间。
而我们的整数集合(intset)可以做到使用较少的内存空间却达到和字典一样效率的实现,但也是前提的,集合中只能包含整型数据并且数量不能太多。整数集合最多能存多少个元素在 redis 中也是有体现的。
OBJ_SET_MAX_INTSET_ENTRIES 512
也就是超过 512 个元素,或者向集合中添加了字符串或其他数据结构,redis 会将整数集合向字典结构进行转换。
一、基本的数据结构
intset 的结构定义很简单,有以下成员构成:
typedef struct intset {
uint32_t encoding;
uint32_t length;
int8_t contents [];
} intset;encoding 记录当前 intset 使用编码,有三个取值:
#define INTSET_ENC_INT16 (sizeof(int16_t))
#define INTSET_ENC_INT32 (sizeof(int32_t))
#define INTSET_ENC_INT64 (sizeof(int64_t))length 记录整数集合中目前存储了多少个元素,contents 记录我们实际的数据集合,虽然我们看到结构体中给数组元素的类型定死成 int8_t,但实际上这个 int8_t 定义的毫无意义,因为这里的处理方式非常规的数组操作,content 字段虽然被定义成指向一个 int8_t 类型数据的指针,但实际上 redis 无论是读取数组元素还是新增元素进去都依赖 encoding 和 length 两个字段直接操作的内存。
基本数据结构还是非常的简单的,下面我们来看看它的一些核心方法。
二、核心 API 实现
1、初始化一个 intset
intset *intsetNew(void) {
intset *is = zmalloc(sizeof(intset));
is->encoding = intrev32ifbe(INTSET_ENC_INT16);
is->length = 0;
return is;
}可见,默认的 inset 配置是使用 INTSET_ENC_INT16 作为数据存储大小,并且不会为 content 数组初始化。常规的数组需要先预先确定数组长度,然后分配内存,继而通过 contents[x] 可以访问数组中任一元素。
但是,inset 这里是非常规式操作数组,encoding 字段定义了数组中每个元素实际类型,lenth 字段定义了数组中实际的元素个数,那么 contents[x] 是失效的,这种方式只会按照 int8_t 进行内存偏移,这种方式是拿不到正确的数据的,所以 redis 中通过 memcpy 按照 encoding 字段的值暴力直接偏移地址操作内存读取数据。
所以,这也是为什么 intset 初始化时不初始化 content 数组的原因所在,因为没有必要。而每当新增一个元素的时候都会去动态扩容原数组的长度以盛放下新插入进来的元素,扩容不会扩容很多,刚好一个新元素所占用的内存即可。具体的细节,我们接着看。
2、添加新元素
intset *intsetAdd(intset *is, int64_t value, uint8_t *success) {
//计算得到新插入的元素的编码
uint8_t valenc = _intsetValueEncoding(value);
uint32_t pos;
if (success) *success = 1;
//如果大于 intset 目前存储元素的编码大小
if (valenc > intrev32ifbe(is->encoding)) {
//触发 intset 升级
return intsetUpgradeAndAdd(is,value);
} else {
//二分搜索当前元素,如果元素已经存在会直接返回
//如果没找到元素,pos 的值就是该元素的位置索引
if (intsetSearch(is,value,&pos)) {
if (success) *success = 0;
return is;
}
//resize 集合,扩容一个元素的内存空间
is = intsetResize(is,intrev32ifbe(is->length)+1);
//移动 pos 后面的元素,以插入我们的新元素
if (pos < intrev32ifbe(is->length)) intsetMoveTail(is,pos,pos+1);
}
//赋值
_intsetSet(is,pos,value);
is->length = intrev32ifbe(intrev32ifbe(is->length)+1);
return is;
}由此,我们应该知道为什么 intset 内的数据是有序且无重复的了,二分查找 O(logN),但是 intset 插入一个元素却不是 O(logN),因为有些情况会触发升级操作,或者极端情况下,会移动所有元素,时间复杂度达到 O(N)。
3、升级
我们先看示意图的变化,然后再分析源码,假设原 intset 使用 16 位的编码存储数据,先来了一个 32 位的数据,触发了我们的编码升级。
原 intset 结构如下:
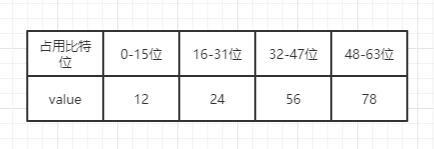
新 intset 结构会扩容成这样:
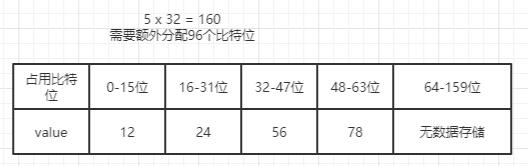
虽然数据占用的内存已经分配好了,但是还需要做的是迁移每个元素占用的比特位。
做法是这样的,假设我们的新元素是 int_32 类型的数值 65536,那么首先我们会将这个 65536 放到[128-159]比特位区间,然后将 78 放到[96-127]比特位区间,并向前以此类推,最后我们会得到升级完成之后 intset。
下面我们看 redis 中代码的实现:
static intset *intsetUpgradeAndAdd(intset *is, int64_t value) {
//intset目前的编码
uint8_t curenc = intrev32ifbe(is->encoding);
//intset即将扩展到的编码
uint8_t newenc = _intsetValueEncoding(value);
int length = intrev32ifbe(is->length);
int prepend = value < 0 ? 1 : 0;
//根据新的元素内存大小重新分配 intset 内存大小
is->encoding = intrev32ifbe(newenc);
is = intsetResize(is,intrev32ifbe(is->length)+1);
//这个地方我先标记一下 @1,下面详细分析
//总体上你可以理解,就是我们上图画的那样,从原集合的最后一个元素
//开始扩大它占用的比特位
while(length--)
_intsetSet(is,length+prepend,_intsetGetEncoded(is,length,curenc));
//将新元素放进 intset 中
if (prepend)
_intsetSet(is,0,value);
else
_intsetSet(is,intrev32ifbe(is->length),value);
is->length = intrev32ifbe(intrev32ifbe(is->length)+1);
return is;
}别的不再解释,我重点解释一下我做标记的 @1,这个循环其实是这个方法的核心点,它完成了将旧元素扩充比特位这么一个操作。
首先明确的一点是,升级操作只有两种情况会触发,一种是新插入一个较大的数值,另一种是新插入一个负很大的值,这两种情况都会导致类型不够存储,需要扩大数据位。
_intsetGetEncoded 这个方法可以根据给定了 length,也就是元素在数组中的下标取出旧数组中对应的元素,很显然,这里是从后往前倒着来的。
因为我们的 intsetResize 方法已经完成了扩容内存的操作,也就是说新元素的内存已经分配完毕,那么 _intsetSet 方法就会将 _intsetGetEncoded 取出的元素重新的向数组中赋值。循环结束时,就是所有元素重新归位的时候,最后再将新元素赋值进入数组最后的位置。
但其实细心的同学会发现,_intsetSet 方法在传下标索引的时候实际传的是 length+prepend,这其实就是我们说,如果 value 是小于零的,length+prepend 最终会导致所有的旧元素往后挪了一个偏移量,然后新的元素会被赋值的索引为零的位置。也就是说,如果新插入的数值是负数,它会被头插进数组的第一个位置。
核心的几个 API 我们都已经介绍了,其他的一些 API 你可以自行参阅源码,相信对你不难。
总结一下,整数集合(intset)使用了非常简洁的数据结构,可以更少的占用内存存储一些整数,但终究是基于数组的,也就避免不了不能存储大量数据的缺点。总体来说,插入一个元素,最好情况 O(logN),最坏的情况是 O(N),摊还时间复杂度为 O(N),查找一个元素,根据索引下标时间复杂度在 O(1)。当 intset 中的元素超过 512 个,或者向其中添加了字符串,redis 会将 intset 转换成字典。
原文:https://www.cnblogs.com/yangming1996/p/11709051.html
本文内容仅供个人学习、研究或参考使用,不构成任何形式的决策建议、专业指导或法律依据。未经授权,禁止任何单位或个人以商业售卖、虚假宣传、侵权传播等非学习研究目的使用本文内容。如需分享或转载,请保留原文来源信息,不得篡改、删减内容或侵犯相关权益。感谢您的理解与支持!