node怎么解决cpu利用低?
Node.js在官网上是这样定义的: “ 一个搭建在Chrome JavaScript运行时上的平台,用于构建高速、可伸缩的网络程序。Node.js采用的事件驱动、非阻塞I/O模型使它既轻量又高效,是构建运行在分布式设备上的数据密集型实时程序的完美选择。”
用Node.js处理I/O密集型任务相当简单,只需要调用它准备好的异步非阻塞函数就行了。
然而数据密集型实时(data-intensive real-time)应用程序并不是只有I/O密集型任务,当碰到CPU密集型任务时,比如要对数据加解密(node.bcrypt.js),数据压缩和解压(node-tar),或者要根据用户的身份对图片做些个性化处理,这时候该怎么办呢?
Node.js是单线程程序,它只有一个event loop,也只占用一个CPU/内核。现在大部分服务器都是多CPU或多核的,当Node.js程序的event loop被CPU密集型的任务占用,导致有其它任务被阻塞时,却还有CPU/内核处于闲置的状态,造成资源的浪费。
cluster 集群
为了充分利用cpu资源,通过类似nginx的master-worker多进程负载处理方式进一步压缩硬件性能,提升nodejs单机服务处理性能。所幸,Node提供了child_process模块,并且也提供了child_process.fork()函数供我们实现进程的复制。
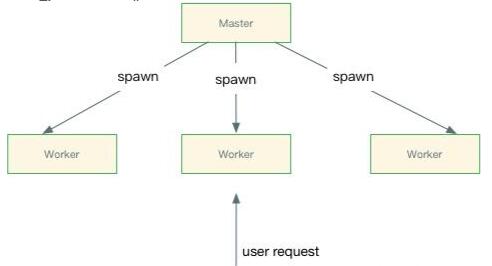
考虑Node单机集群健壮性,平滑重启,性能等因素,NodeV0.8直接引入了cluster模块来处理,用以解决多核CPU的利用率问题,同时也提供了较完善的API,用以处理进程的健壮性问题。
cluster工作原理
事实上cluster模块就是child_process和net模块的组合应用。Cluster启动时,Cluter内部隐式创建TCP服务器,在cluster.fork()子进程时,将这个TCP服务器端socket的文件描述符发送给工作进程。如果工作进程中存在listen()侦听网络端口的调用,它将拿到该文件描述符,通过SO_REUSEADDR端口重用,从而实现多个子进程共享端口。
cluster事件
对于健壮性处理,cluster模块也暴露了相当多的事件。
Fork: 复制一个工作进程后触发该事件
Online: 复制完一个工作进程后,主进程收到消息后触发该事件
Listening:工作 进程调用listen(),主进程收到消息后触发该事件
Disconnect:IPC通道断开后触发该事件
Exit: 有工作进程退出时触发该事件
Setup: cluster.setupMaster()执行后触发该事件
源码示例:
Worker.js 用于创建单个服务,并且计算斐波那契数列。
let http = require('http');
// let port = Math.round((1 + Math.random())*1000);
let port = 8882;
console.log(`Server running at http://localhost:${port}/`);
http.createServer((req, res) => {
let n = fibonacci(42);
res.end(n + '');
}).listen(port);
function fibonacci(n) {
if (n === 0 || n === 1)
return n;
else
return fibonacci(n - 1) + fibonacci(n - 2);
}Cluster.js 主进程,根据cpu数量复制多个进程。
let cluster = require('cluster');
cluster.setupMaster({
exec: "worker.js"
});
let cpus = require('os').cpus();
for (var i = 0; i < cpus.length; i++) {
cluster.fork();
}本文内容仅供个人学习、研究或参考使用,不构成任何形式的决策建议、专业指导或法律依据。未经授权,禁止任何单位或个人以商业售卖、虚假宣传、侵权传播等非学习研究目的使用本文内容。如需分享或转载,请保留原文来源信息,不得篡改、删减内容或侵犯相关权益。感谢您的理解与支持!