通过编译器插件实现代码注入
原文:通过编译器插件实现代码注入 | AlloyTeam
作者:林大妈
背景问题
大型的前端系统一般是模块化的。每当发现问题时,模块负责人总是要重复地在浏览器中找出对应的模块,略读代码后在对应的函数内打上断点,最终开始排查。
大部分情况下,我们会选择在固定的位置(例如模块的入口,或是类的构造函数)打上断点。也就意味着打断点的过程对于开发者来说是机械的劳动。那么有没有办法在不污染源代码的基础上通过配置来为代码打上断点呢?
实现思路
要想不污染源代码,只能选择在编译时进行处理,才能将想要的内容注入到目标代码中。代码编译的基本原理是将源代码处理成单词串,再将单词串组织成抽象语法树,最终再通过遍历抽象语法树并转换上面的节点而形成目标代码。
因此,代码注入的关键点就在于在抽象语法树形成时对语法树节点进行处理。前端代码通常会使用 babel 进行编译。
熟悉 babel 的基本原理
babel 的组成
babel 的核心是 babel-core。babel-core 可被划分成三个部分,分别处理对应的三个编译过程:
- babel-parser —— 负责将源代码字符串“单词化”并转化成抽象语法树
- babel-traverse —— 负责遍历抽象语法树并附加处理
- babel-generator —— 负责通过抽象语法树生成目标代码
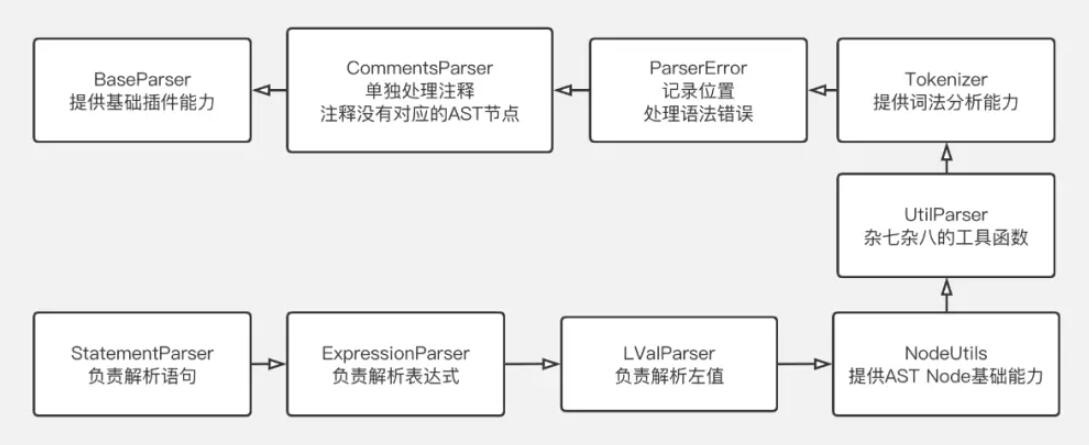
babel-parser
整个 babel-parser 使用继承的方式,根据功能的不同逐层包装:
tokenizer
babel-parser 的一个核心是“tokenizer”,可以理解为“单词生成器”。babel 维护了一个 state(一个全局的状态),它会通过记录一些元信息提供给编译器,例如:
- “这段 JavaScript 代码是否使用了严格模式?”
- “我们现在识别到第几行第几列了?”
- “这段代码里有哪些注释?”
tokenizer 的内部定义了不同的方法以识别不同的内容,例如:
- 读到引号时通过 readString 方法尝试生成一个字符串 token
- 读到数字时通过 readNumber 方法尝试生成一个数字 token
LVal/Expression/StatementParser
babel-parser 的另一个核心是“parser”,可以理解为“语法树生成器”。其中,StatementParser 是子类,当我们引入 babel-parser 并调用 parse 方法时,识别过程将从此处启动(babel 应该是将整个文件认为是一个语句节点)。
同样地,这些 parser 的内部也都为识别不同的内容而定义不同的方法,例如:
- 识别到 true 时,生成一个 Boolean 字面量表达式
- 识别到 @ 这个符号时,生成一个 装饰器语句节点
babel-traverse
babel-traverse 提供方法遍历语法树。它使用访问者模式,为外界提供添加遍历时附加操作的入口。
在访问者模式(Visitor Pattern)中,我们使用了一个访问者类,它改变了元素类的执行算法。通过这种方式,元素的执行算法可以随着访问者改变而改变。
TraversalContext
遍历语法树时,babel 同样定义了一个 context 判断是否需要遍历以及遍历的方式。
TraversalContext 先将节点和外来的访问者进行有效化的处理,然后构造访问队列,最后启动深度优先遍历整棵语法树的过程。
class TraversalContext {
// ...
visitQueue(queue: Array<NodePath>) {
// 一些预处理
// 深度优先遍历
for (const path of queue) {
if (path.visit()) {
stop = true;
break;
}
}
// ...
}
// ...
}visitor
babel 使用的访问者模式,非常地利于开发者编写插件。编写 babel 插件的核心思路就是编写 visitor,以附加对语法树进行的操作。
在 babel 中,visitor 是一个对象(可以通过 babel 的 ts 声明文件找到类型规范),通过在这个对象中新增 key(需要访问的节点)和 value(执行的函数)可以使遍历语法树时对应执行指定的操作:
// 如:编写一个插件,每次遍历到标识符时就输出该变量名
const visitor = {
Identifier(path, state) {
console.log(path.node.name);
},
};
// 或
const visitor = {
Identifier: {
enter(path, state) {
console.log(path.node.name);
},
exit() {
// do nothing...
},
},
};path
path 是每个 visitor 方法中传入的第一个参数,它表示树上的该节点与其它节点的关系。编写 babel 插件,最核心的是了解并利用好 path 上挂载的元数据以及对外暴露的 API。
path 上有以下相对重要的属性:
- node 节点
- parent 父节点
- parentPath 父节点的 path
- container 包含所有同级节点的元素
- context 节点对应的 TraversalContext
- contexts 节点对应的多个 TraversalContext
- scope 节点的作用域
- ……
path 的原型上还挂载了许多其它的处理方法:
- get (静态方法)获取节点的属性
- insertBefore 在当前节点前增加指定的元素
- insertAfter 在当前节点后增加指定的元素
- unshiftContainer 将指定的节点插入该节点的 container 的首位
- pushContainer 将指定的节点插入该节点的 container 的末位
- ……
state
state 表示当前遍历的状态,记录了一些元信息,与 tokenizer 的 state 类似。
babel-generator
babel-generator 主要实现了两个功能:
- 使用缓冲区分步生成目标代码
- 源码映射(sourcemap)
babel-generator 暴露了 generate 函数,接收语法树、配置以及源代码为参数。其中,语法树用于生成目标代码,而源代码用作 sourcemap。babel-generator 中的代码业务逻辑较多,没有太过复杂的设计,但拆分函数非常细,所有的判断以及不同种符号的处理都被拆开了,新增功能非常简单。
Buffer
buffer 中定义了一个存放目标代码的字符串数组,以及一个存放末尾符号(空格、分号以及'n')的队列。字符串数组采用按行插入的方式。存放末尾符号的队列用以处理行末多余的空格(即每次插入末尾符号前 pop 出所有的空格)。
SourceMap
babel-generator 采用了 npm library source-map 来构建 sourceMap。babel 在输出代码时,只要位置不是在目标代码的换行处,都会进行一次标记以提供参数给 source-map 库,目前 source-map 库具体内容还未细致研究。
插件的具体实现
了解 babel 以后,结合我们的需求,基本目标可定为:编写可配置的 babel 插件,使开发人员通过配置文件在特定位置下放断点。
babel 插件的核心是 visitor,这里我们举一个具体而特殊的例子来描述如何实现以上的目标:
将特定的注释替换成调试语句
首先,应从 babel 构造的语法树上找到对应的注释节点。但我们发现,在 babel 构造的语法树中,无论何种注释,都不是一个具体的节点:
例如,对于以下的代码:
// @debug
const a = 1;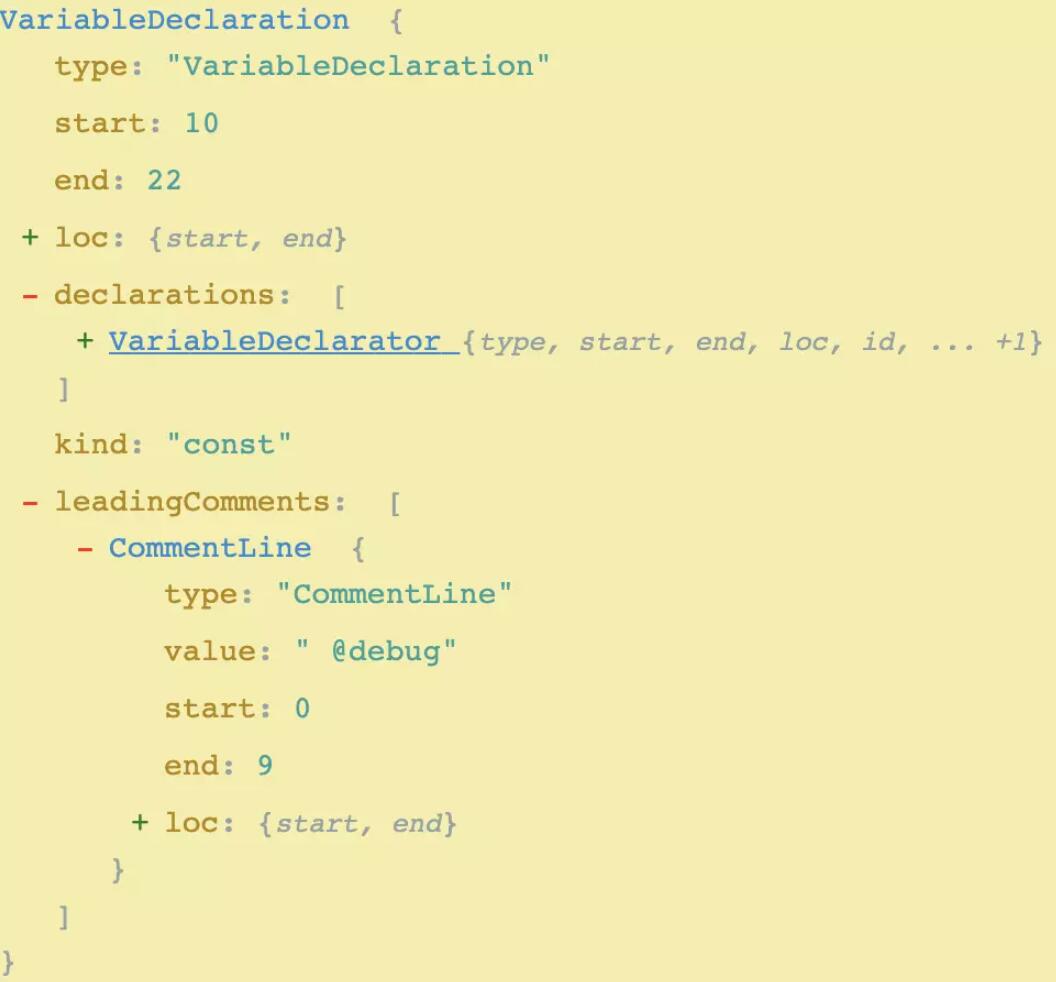
在它的语法树中,注释节点只属于某段具体的代码的"leadingComments"属性,而非独立的树节点。再考虑以下代码:
const a = 1;
// @debug
const b = 2;
在它的语法树中,注释节点既属于第一段的"trailingComments"属性,也属于第二段代码的"leadingComments"属性。包括代码和注释同行,结果也是相同的。
因此,在编写 visitor 前,需要注意两个点:
- 注释并不是特定的语法树节点,而是节点上的一个属性。
- 遍历所有语句时,前一句的"trailingComments"和后一句的"leadingComments"会发生重复。
采取的解决方案是:
- 直接在 visitor 中添加"CommentLine"属性进行处理是无用的。可选择在 traverse 时使用"enter"方法统一检测所有节点的前后注释。
- “后顾”,当前节点有"trailingComments"需要替换时,要遍历后一个兄弟节点的"leadingComments"进行去重,或者每次替换时直接将注释内容删除。
完整的 visitor 代码如下:
export const visitor = {
enter(path) {
addDebuggerToDebugCommentLine(path);
// 添加其它的处理方法……
},
};
// 通过key值防止重复
let dulplicationKey = null;
function addDebuggerToDebugCommentLine(path) {
const node = path.node;
if (hasLeadingComments(node)) {
// 遍历所有的前缀注释
node.leadingComments.forEach((comment) => {
const content = comment.value;
// 检测该key值与防重复key值相同
if (path.key === dulplicationKey) {
return;
}
// 检测注释是否符合debug模式
if (!isDebugComment(content)) {
return;
}
// 传入参数,插入调试代码
path.insertBefore();
});
}
if (hasTrailingComments(node)) {
// 遍历所有的后缀注释
node.trailingComments.forEach((comment) => {
const content = comment.value;
// 检测注释是否符合debug模式
if (!isDebugComment(content)) {
return;
}
// 防止下一个sibling节点重复遍历注释
dulplicationKey = path.key + 1;
// 传入参数,插入调试代码
path.insertBefore();
});
}
}上述的例子之所以说特殊,是因为注释不是语法树上的节点,而是节点上的一个属性。当仅需要识别某类节点时,方法就更为简单了,直接通过为 visitor 定义更多的方法即可完成:
export const visitor = {
Expression(path) {
addDebuggerToExpression(path);
},
Statement(path) {
addDebuggerToStatement(path);
},
// 添加其它需要的方法……
};当出现更复杂的情况(例如要在调试语句中传入参数)时,丰富以上的函数。通过使用解析注释或在 webpack loader 中解析配置项文件获得参数,对应传入即可。
用途
根据以上的代码编译出的代码是经过处理后的代码。它部署到某个测试环境后,有以下的用途:
- 灰度某个用户,即可随时排查该用户的使用问题。
- 在项目中增加不污染源代码的配置文件,使开发人员通过配置下放指定代码。
- 甚至还可以增加可视化界面进行配置。
通用化
了解插件知识后,我们可以总结出插件的最大特点:几乎可以在代码任意处修改任意内容。理论上,只要逻辑打通,语法树有无穷的玩法。例如刚才提到的根据配置下放调试代码和常见的单测覆盖率统计等。
因此,还可以对插件进行更高级的抽象,做成插件工厂,可供用户配置生成对应功能的插件并重新执行编译等。
本文内容仅供个人学习、研究或参考使用,不构成任何形式的决策建议、专业指导或法律依据。未经授权,禁止任何单位或个人以商业售卖、虚假宣传、侵权传播等非学习研究目的使用本文内容。如需分享或转载,请保留原文来源信息,不得篡改、删减内容或侵犯相关权益。感谢您的理解与支持!