HTTP缓存总结(浏览器缓存)
标题虽然叫HTTP缓存,但叫浏览器缓存也可以,HTTP算是君子,浏览器算是小人,君子动口定下协议,小人动手实现协议。
缓存概念
先看一下缓存的目的,主要还是基于性能的考虑
- 缓存减少了冗余的数据传输,节省了你的网络费用
- 缓存缓解了网络瓶颈的问题,不需要更多的带宽就能够更快地加载页面
- 缓存降低了对原始服务器的要求,服务器可以更快地响应,避免过载的出现
- 缓存降低了距离时延,因为可能是从CDN或者代理服务器拿到缓存,这样子比原始服务器可能更快
整个Web应用可不只有HTTP缓存,还有代理服务器缓存、CDN缓存,另外后端有自己的应用逻辑缓存、数据库缓存等,反正就秉持一个原则, 能利用缓存的就尽量利用缓存 ,用空间换时间。
针对缓存同时还有缓存雪崩、缓存穿透、缓存击穿等概念,这里不展开细述。
不过对于一个前端人员来说,可以把精力主要放在HTTP缓存上,该机制和浏览器狼狈为奸[狗头],提高了Web应用的性能。
long long ago
先从过去讲起,这里介绍已经过时的用法,有个概念即可
在HTTP1.0里使用的是 Expires 头,现在的一些工具、框架里,比如nginx配置 expires 1d 后,也会自动帮你把这个 Expires 头给带上,但其实当有 Cache-Control 头存在的时候, Expires 是不起作用的。
我们看一个 Expires 头的实际例子
expires: Tue, 14 Dec 2021 10:56:15 GMT注意两个地方,一个是它使用了绝对时间,另一个是时间的精确度是秒级,那么就存在两个问题,一个是绝对时间可能在操作系统时间修改或者跨时区(服务器在一个时区,浏览器在另一个时区)的情况下出现问题,另一个就是万一秒级的精确度还不够,在一秒内发生资源变化呢?
还有一个遗留的缓存有关的HTTP头是 Pragma ,它只能被设置为 no-cache ,效果和 Cache-Control: no-cache 一样
Pragma: no-cache别看 Pragma 是一个遗老遗少,但它的优先级比较高,也即是 Pragma > Cache-Control > Expires
现在
由于 Expires 存在之前所述的缺陷,在HTTP1.1的时候又提出了一个新的 Cache-Control 头,用下面这张表显示它可以设置的值,内容出自MDN
| 缓存资源,但在发布缓存副本之前,强制要求缓存把请求提交给原始服务器进行验证(协商缓存验证) | |
| no-store | 缓存不应存储有关客户端请求或服务器响应的任何内容,即不使用任何缓存 |
| private | 表明响应只能被单个用户缓存,不能作为共享缓存(即代理服务器不能缓存它)。私有缓存可以缓存响应内容,比如:对应用户的本地浏览器 |
| public | 表明响应可以被任何对象(包括:发送请求的客户端,代理服务器,等等)缓存,即使是通常不可缓存的内容。(例如:1.该响应没有max-age指令或Expires消息头;2. 该响应对应的请求方法是 POST ) |
| max-age=[seconds] | 设置缓存存储的最大周期,超过这个时间缓存被认为过期(单位秒)。与Expires相反,时间是相对于请求的时间 |
| s-maxage=[seconds] | 覆盖max-age或者Expires头,但是仅适用于共享缓存(比如各个代理),私有缓存会忽略它,只适用于供多位用户使用的公共缓存服务器(比如CDN缓存) |
| s-maxage=[seconds] | 表明客户端愿意接收一个已经过期的资源。可以设置一个可选的秒数,表示响应不能已经过时超过该给定的时间 |
| min-fresh=[seconds] | 表示客户端希望获取一个能在指定的秒数内保持其最新状态的响应 |
| must-revalidate | 一旦资源过期(比如已经超过max-age),在成功向原始服务器验证之前,缓存不能用该资源响应后续请求 |
| proxy-revalidat | 与must-revalidate作用相同,但它仅适用于共享缓存(例如代理),并被私有缓存忽略 |
| no-transform | 不得对资源进行转换或转变。Content-Encoding、Content-Range、Content-Type等HTTP头不能由代理修改 |
| only-if-cached | 表明客户端只接受已缓存的响应,并且不要向原始服务器检查是否有更新的拷贝 |
Cache-Control 用在请求里可以指定
Cache-Control: max-age=<seconds>
Cache-Control: max-stale[=<seconds>]
Cache-Control: min-fresh=<seconds>
Cache-control: no-cache
Cache-control: no-store
Cache-control: no-transform
Cache-control: only-if-cachedCache-Control 用在响应里可以指定
Cache-control: must-revalidate
Cache-control: no-cache
Cache-control: no-store
Cache-control: no-transform
Cache-control: public
Cache-control: private
Cache-control: proxy-revalidate
Cache-Control: max-age=<seconds>
Cache-control: s-maxage=<seconds>以下是几个典型的设置
禁止缓存
Cache-Control: no-store
Cache-Control: max-age=0 # 当服务器关闭或失去连接时,使用了缓存缓存
Cache-Control: public, max-age=31536000需要重新验证
Cache-Control: no-cache需要重新验证
Cache-Control: max-age=0, must-revalidate注意以下设置当服务器关闭或失去连接时,会使用缓存
Cache-Control: max-age=0关于如何选择,我画如下的图,逻辑出自于Google自己的文档
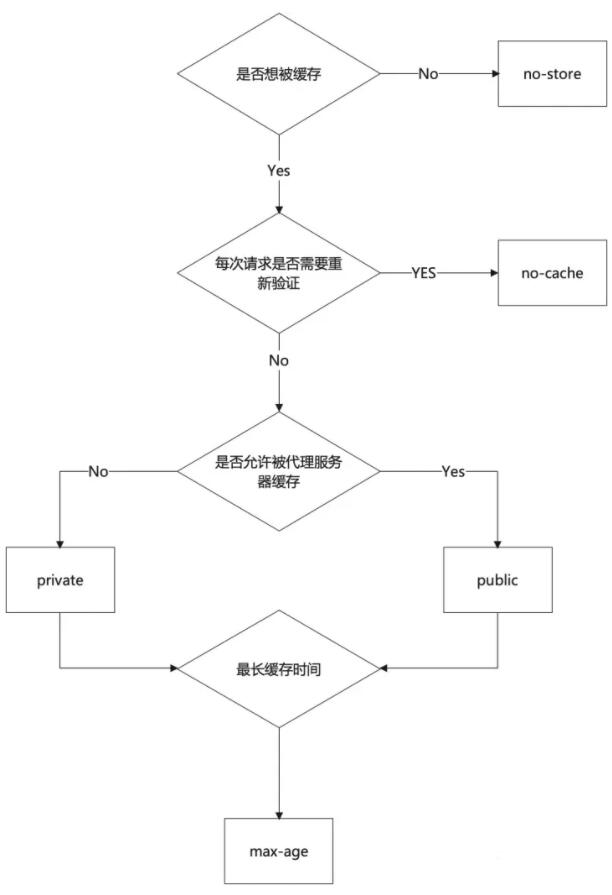
除了 no-store ,其他选项都会缓存资源(但是不是直接使用是另一个问题了,要就是存不存看 no-store ,用不用、怎么用还要取决于其他的设置)。一般情况下,都会用 max-age 来指定资源的缓存时长,在该时长范围内,命中缓存,直接使用本地资源。
缓存后的资源有可能在内存里(from memory cache)也有可能在磁盘(from disk cache)上,通过Chrome的开发者工具里的Network页签能够看出来
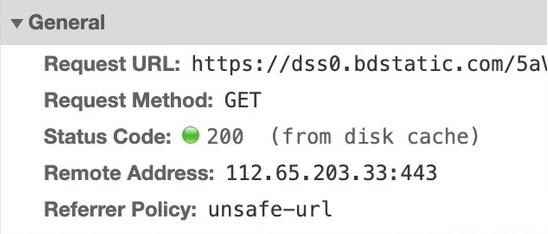
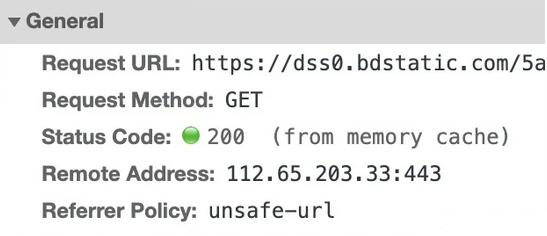
浏览器肯定先读取内存再读取磁盘,毕竟内存更快。一般来说CSS文件由于构建StyleSheet之后就不再使用了,会优先放在磁盘,而JS和图片会优先放在内存。不过缓存资源具体放在哪其实不重要也不用过多纠结,因为一旦命中了缓存,最最耗时的网络请求就不需要发送了,另外放在内存还是放在磁盘这也不是你想控制就能控制得了的。
以上 Expires 和 Cache-Control 判断缓存的方式称为 强缓存 ,强缓存是连HTTP请求都不需要发送的,直接本地闭环。
花开花落花落花开,假如现在超过了 max-age 里所设置的时间,那么是否要完全重新下载资源呢,答案当然是否定了,如果资源的大小有1G,并且没有发生变化,难不成也傻傻的重新下载一遍么?
这个时候就有两对HTTP头来辅助服务端识别资源是否修改
Last-Modified / If-Modified-Since
Last-Modified 是服务器响应返回时,返回该资源文件在服务器最后被修改的时间。
If-Modified-Since 则是浏览器再次发起该资源请求时,携带上次请求返回的Last-Modified值,通过此字段值告诉服务器该资源上次请求返回的最后被修改时间。
last-modified: Sat, 09 Oct 2021 06:42:14 GMTEtag / If-None-Match
Etag 是服务器响应返回时,返回当前资源文件的一个唯一标识,一般会对资源内容进行Hash计算得到一个Hash编码。
If-None-Match 是客户端再次发起该资源请求时,携带上次请求返回的唯一标识 Etag 值,通过此字段值告诉服务器该资源上次请求返回的唯一标识值。
etag: W/"616139c6-dd4"注意 Etag / If-None-Match 享有更高的优先级,因为
Expires
Last-Modified
Last-Modified假设服务器现在判断出了资源并没有修改,那么它就可以直接返回状态码304,而304对应的状态描述就是Not Modified,这就是告诉浏览器,资源没有发生变化,你还继续用原来的就成,当然此时浏览器也会根据响应的HTTP头更新相关的缓存设置;如果服务器发现资源已经发生了变化,那么就跟第一次请求一样,返回状态码200,并且把资源放入到body里返回。
以上两对辅助的HTTP头判断缓存的方式称之为 协商缓存 ,与强缓存相比,它还是要发送一次请求的,只是有可能这个请求的响应比较轻,只带了304的状态码而不用带资源内容。
一个实例
现在用一个请求流程来看一下缓存使用的过程,假设我需要使用到 /abc.css 这个资源
- 现在是第一次请求,没有缓存,那么这个请求就被发送出来并且得到的响应就是状态码200且在body放入了资源的内容
- 浏览器拿到这个响应后,就把资源缓存下来(假设hi了 max-age 设为1分钟)
- 在1分钟内,强缓存生效,再次请求 /abc.css 的时候,这个HTTP请求压根儿就不会发出去,直接使用缓存下来的资源
- 现在超过了1分钟的缓存时间,那么就轮到协商缓存上场了,带有 If-None-Match 和 If-Modified-Since 头的请求被发往服务器
- 服务器根据自己的逻辑判断,假设它识别该资源没有变化,那么就发给状态码为304的响应回去,不用带资源内容
- 浏览器拿到这个304状态码后就知道这个资源还没有发生改变,继续使用缓存下来的资源,并更新缓存设置
- 假设服务器根据自己的逻辑判断识别出资源发生了变化,那么就重复1、2步
这里盗一张图吧,懒得自己画了
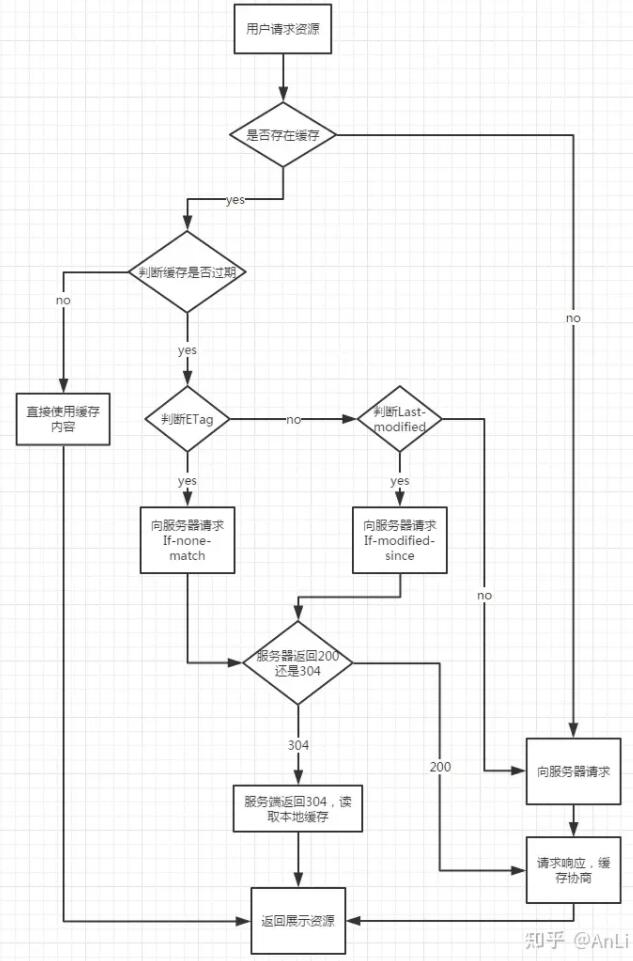
缓存生效
下表来表示缓存在什么操作下会生效或者失效
| 操作 | Expires/Cache-Control | Last-Modified/Etag |
|---|---|---|
| 地址栏回车 | 有效 | 有效 |
| 页面链接跳转 | 有效 | 有效 |
| 新开窗口 | 有效 | 有效 |
| 前进后退 | 有效 | 有效 |
| F5刷新 | 无效 | 有效 |
| Ctrl + F5强制刷新 | 无效 | 无效 |
总结一下,一般的正常操作都会使用到缓存,只是以下两种情况例外
- 在F5刷新的时候(这里用Windows中常用的快捷键来替代)在 请求头 (注意!)加上 Cache-Control: max-age=0 ,强缓存被强制失效,使用协商缓存
- 而在Ctrl + F5刷新的时候,在 请求头 (注意!)加上 Cache-control: no-cache ,同时会删除协商缓存字段 if-modified-since 和 if-none-match ,这样协商缓存也被强制失效了,相当于在开发者工具的Network里勾选上Disable cache,每次都是完整请求资源

现实中
现实中觉得这个协商缓存304也是浪费的,白白耗费一次请求,所以搞起了“消灭304”运动。想办法把识别资源的标志放入到URL中,因为URL就相当于是缓存的key,只要URL有一丁点不一样,缓存就不会生效(这也是为什么在不想使用缓存的时候就会带上一个 ?random= 1234567890 查询字符串)。
之前的做法是放入版本号,比如 abc.v1.css ,不过现在主流的做法是放入资源的hash值,比如 abc.7dfkm6.css ,并且资源会设一个很长的缓存失效期,比如一年。但是要记住,对于SPA应用来说,入口的 HTML 文件千万不能缓存,因为在 HTML 中引用了各资源文件,它一旦被缓存那么整个应用就得不到更新了,而且还会出错,因为很可能在升版后,原来的资源 abc.7dfkm6.css 已经不存在了。
无法被浏览器缓存的请求
- HTTP 信息头中包含 Cache-Control: no-cache , pragma: no-cache ,或 Cache-Control: max-age=0 等告诉浏览器不用缓存的请求
- 需要根据 Cookie,认证信息等决定输入内容的动态请求是不能被缓存的
- 经过 HTTPS 安全加密的请求
- POST 请求无法被缓存
- HTTP 响应头中不包含 Last-Modified/Etag ,也不包含 Cache-Control/Expires 的请求无法被缓存
HTTP缓存之外
这里刨去过时的技术,比如 manifest 描述文件来进行离线缓存
一方面是可以写自己业务所需逻辑的缓存,比如使用localStorage、IndexDB、cache storage API(注意它不是只能用在Service Worker里)、File API等,不过要留心浏览器兼容性问题
另一方面可以使用新的技术,比如PWA,它的Service Worker就相当于是一个可以自主控制的缓存体系,它更多针对了离线应用场景。从下面这张图(我还没做实验,也没找到该图的出处)来看Service Worker的优先级更高
原文 https://zhuanlan.zhihu.com/p/438789495
本文内容仅供个人学习、研究或参考使用,不构成任何形式的决策建议、专业指导或法律依据。未经授权,禁止任何单位或个人以商业售卖、虚假宣传、侵权传播等非学习研究目的使用本文内容。如需分享或转载,请保留原文来源信息,不得篡改、删减内容或侵犯相关权益。感谢您的理解与支持!


