React 开发者一定要知道的底层机制— React Fiber Reconciler
React 自从v16 以后就推出了React Fiber 这个全新的底层架构,React 底层使用fiber 架构重构后才得以实现一些features 例如Concurrent Mode 与Suspense Data Fetching,虽然这些功能都还在实验阶段,但我想未来势必会成为React 稳定的features,可以看出React Fiber 对于整个React 生态圈的重要性。我认为要变成一个更好的开发者,尝试去理解框架底层的source code 实践与尝试reverse engineering 的过程是非常有帮助的。其实关于React Fiber 的学习资源应该不少,这篇文章中我想按照自己的步调与理解尝试介绍React Fiber 的运作机制,不会到太过深入,但相信能对React Fiber 的运作机制有基本的了解,那我们就开始吧!
什么是React Fiber ?
曾经写过class component 的React 开发者应该都经历过React 16 所带来的巨变— 也就是React Hooks,基本上大大的改变了开发的模式。然而除了明显可以看见的程式码风格改变以外,其实React 也在这时针对内部的实作与架构进行了重构,也就是React Fiber Architecture,这个架构也是React 未来许多功能例如Concurrent Mode 得以实践的基础。
(补充:其实React Hooks 得以实现也是因为React 使用fiber架构重构喔!)
以宏观的角度来看React Fiber 指的是source code 经过重构后的一种全新架构, 不过如果以狭义的角度来看,fiber 其实是一个拥有许多特定属性的JavaScript 物件,长得像下面这样:

而fiber 也代表着「An unit of work for React to process」,也许有点抽象难懂,但目前为止我们先停在这里,随着文章段落的推进我们会对fiber 有更加深入的理解。
fiber能做什么?
重构后的React Fiber 架构改变了什么?我觉得可以将重点放在两个地方上:
- Animation 动画
- Responsiveness 反应能力
从上面这张gif 可以明显的做出对比,左边是fiber 以前的架构,右边则是在fiber 架构下的体验,可以发现动画的流畅度差了非常多,至于反应能力(例如mouse hover 等event)则可以到以下两个版本的范例网站看看差别:
当然在一般的应用下是不会有这么明显的差别的,以上的范例都是刻意为之的,但当你的应用非常复杂并且非常吃效能时,以上的状况就有可能会发生。
fiber 架构可以达成这样的改变主要可以归因于:
- fiber 可以将页面渲染的任务切分成chunks
- 不同的任务可以经过prioritize 区分优先级
- 任务可以暂停,之后再继续执行(这也是将任务分优先级的目的,当做到一半出现更高优先级的任务的时候,会希望可以先暂停目前工作的执行,等处理完高优先及任务后再回来继续执行)
- 可以重复使用之前的work,也可以将不需要的work 丢弃掉
现代的web 应用中最想要避免的无非是两种糟糕的使用者体验— 「页面卡顿」与「没有内容的白屏画面」,会造成这两种问题的原因很大的机会是出自于CPU 的瓶颈(元件层级深且复杂、耗性能的运算、设备本身CPU 性能不足…等等)与IO 的瓶颈(网路请求),而react fiber 就是为了解决这些问题而诞生的架构。
JSX -> React Element -> Fiber Node
React 开发者自然对于JSX 语法十分熟悉,React 在背后会呼叫 React.createElement这个function 来将JSX 中的elements 转换成React Elements。

从上图可以知道React Element 也是一个JavaScript 的物件,记载了element 的一些properties 例如type、key、props 等等,在fiber 架构下,react 还会透过呼叫createFiberFromTypeAndProps这个function 将React Elements 转换成Fiber Nodes。

我们可以归纳一下到目前为止对于fiber 的认知:
- 会形成一个由fiber nodes 串连起来的tree(我们都知道在写component 的时候是树状结构,理所当然由它转换而来的React Elements 与接着由React Elements 再次转换而成的fiber nodes 也会是树状结构)
- fiber node 其实也代表了React Element,但它涵盖了更多属性
- fiber = unit of work for react to process
- React Fiber 会经过两阶段的处理过程:1. Render Phase(非同步)2. Commit Phase(同步)
各位会比较疑惑的应该是最后一点,这在稍后会进一步说明。
React Reconciliation
谈到React 怎么更新我们的画面,大家应该都知道React 透过Virtual DOM 还有Diff 演算法算出画面中实际需要更新的部分,比对更新前后virtual DOM 的差异之后,再去更动真实的DOM,有效减少渲染的次数,而这个Diff 的过程也被称作reconciliation。
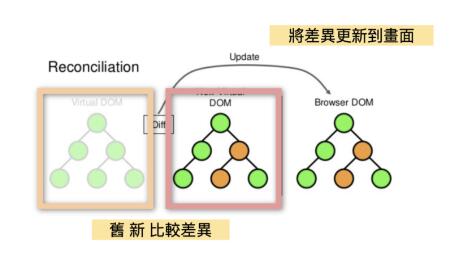
React 实作了一个「启发式(heuristic)演算法」将原本需要O(n³) 的diff 流程压到了O(n),靠的是两个假设:
- 两个不同类型的element 会产生出不同的tree。
- 开发者可以通过key prop 来指出哪些child elements 在不同的render 下可以保持不变。
会提到React Reconciliation 是因为fiber 的出现最主要改变的就是React 的Reconciliation 流程,这稍后会再进阶说明。如果对于启发式演算法有兴趣的朋友可以参考我同事Ken 的简报。
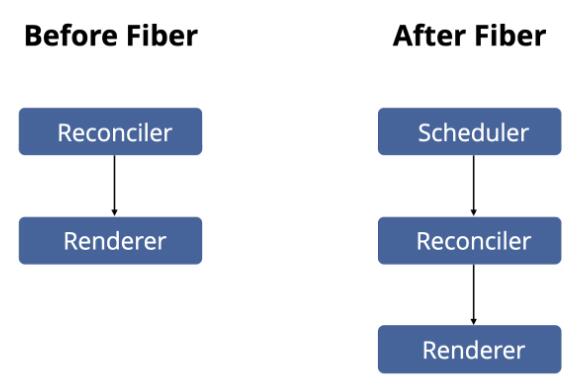
在fiber 架构以前React 渲染页面时主要会经过两个阶段:
- Reconciler — 负责找出需要变动的元件,也就是上面提到的演算法,这个阶段可以再细分成两个stage:render phase 与commit phase。在render phase 这个阶段React 会更新数据生成新的Virtual DOM,然后通过Diff 演算法,找出需要更新的元素,放到update queue 中,最后得到新的update queue,commit phase 这个阶段React 会遍历update queue ,将其中需要的变更「一次性」更新到DOM 上。
- Renderer — 负责将变化的元件渲染到画面上。熟悉React 生态系的开发者应该听过可以使用React 来开发除了网页以外的应用,例如React Native 可以用来开发手机App、react-360可以用来开发VR 应用,这其实是因为React 将reconciliation 等核心实作在react core library 当中,实际上如何渲染到应用上则交由不同renderer 来处理,这也是「大前端时代」得以实现的契机之一。如果对于其他React 相关的renderer 有兴趣,可以参考awesome react renderers这个github repo。
在fiber 架构出现以后,多了一个scheduler 的机制。为什么多了scheduler ? 前面有提到fiber 让任务可以切分成chunks 并且可以区分优先级,因此在fiber 架构后还会经过一层scheduler 来调度工作,而reconciler 这个步骤的运作机制也经过调整,等等会再说明。
Old Reconciler — Stack
在React15 及以前,Reconciler 采用递回的方式创建virtual DOM (熟悉functional component 的话应该可以了解这个概念,我们是透过呼叫component 的function 来得到要return 的元件,这个过程遇到子元件就得再去呼叫子元件的function,于是形成call stack 的结构),递回的过程是不能中断且是同步的,如果元件树的层级很深,递回会占用main thread 很多时时间,这会产生相应的一些问题例如造成页面卡顿、使用者的事件没有回应…等等。
为了解决这个问题,React 想要将这种递回且无法中断的更新refactor 成非同步且可以中断的更新,而曾经依靠递回的Virtual DOM 资料结构明显是没办法满足这个条件的,于是全新的React Fiber 架构就因此诞生了。所以通常在React 16 之后的Reconciler 也被称作Fiber Reconciler,而Virtual DOM 这个名词React 官方也有提到说为了怕搞混,在fiber 架构出现后会尽量避免使用这个名词。我认为可以看成React Fiber 一样要创建一个虚拟的树状结构,但是结构跟以前的Virtual DOM tree 版本已经不一样了,所以通常会称作fiber tree 以免使开发者搞混。
fiber遍历组件树?
这个标题其实就已经直接破梗了,在fiber 架构下是使用linked list 这个资料结构来遍历component tree 的,这个小段落会提到在fiber 架构出现前react 是如何遍历component tree 的,以及以前的方式有哪些缺点导致要使用fiber 重构,最后是为什么使用linked list 的方式可以解决之前的问题。

如果对于Linked List 这个资料结构完全不理解的朋友可以参考我同事PJ 的文章。
浏览器在一帧里面都做了些什么事?
在正式进入主题之前,首先我们要先回顾一下浏览器在一帧里面都做了些什么事,为什么呢?稍后就知道了。
我们都知道页面的内容都是一帧接着一帧绘制出来的,browser 的frame rate (fps, frame per second) 代表浏览器一秒可以绘制多少帧。原则上一秒绘制的帧数越多,画质也就越细致。目前浏览器的解析度大多是60 fps,每一帧大约耗费16.6ms 左右(1000ms / 60)。那在这一帧(16.6ms) 中browser 经历了哪些流程并做了哪些工作呢?
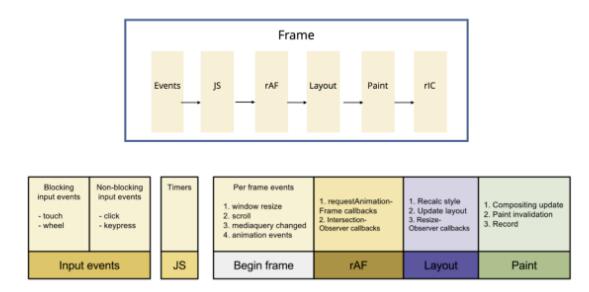
从上面两张图来看,大致上可以归纳出浏览器在一帧内会经历这些过程:
- 接受使用者的input event (click, keypress 等事件)
- 执行事件的callback
- 执行rAF (RequestAnimationFrame)
- 页面的layout 与样式计算
- 绘制渲染页面
- 执行rIC (RequestIdleCallback)
最后一步的rIC 事件不是每一帧结束都会执行,只有在一帧的16.6ms 中做完了前面的流程并且还有剩余的时间才会执行。(关于rIC 我在了解SWR 的运作机制,How this async state manager works ?这篇文章也有稍微提到过,其实SWR 的cache revalidation 机制就是透过rIC 与rAF 来达成的)
不过要特别注意的是,如果有剩余价值的时间可以执行rIC,那么下一帧就需要在rIC 的callback 执行结束后才能继续渲染,所以建议在rIC 不要执行一些耗时的操作,如果太久没有将控制权交还给browser,将会影响下一帧的渲染,导致画面出现卡顿或对于事件的延迟反应。
渲染阶段
刚刚有提过在Fiber Reconciler 有两个阶段— render phase 与commit phase,我们现在主要focus 在第一个阶段render phase,React 在render phase 到底做了哪些事呢?
从组件中检索子级
更新状态和props
调用生命周期挂钩
将它们与以前的子级进行比较,并找出需要执行的DOM更新
嗯…那有什么问题吗?
React 会以「同步」的方式走过整个component tree 并且做一些相对应的work,这边的work 指的是前面提及的比如说更新state 与props、执行一些lifecycle method、比较更新前后的差异找出需要更新DOM 的节点…等等。
如果这些工作所耗费的时间超过16ms,就有可能会造成「掉帧」的状况,使用者看到的画面就有可能是非常卡顿与不流畅的,这对于前端应用来说当然是需要尽量避免的状况。
那有没有什么方法可以解决这个问题呢?这时刚刚提到的rIC 与rAF 就派上用场啦!
rAF, rIC to the rescue
刚刚其实就有提过rAF 与rIC 在浏览器一帧的执行时间点,React core team 想到可以利用rAF 与rIC 来执行reconciler render phase 的这些任务,于是React 将一些高优先级的任务比如说animation 放到rAF 去处理,而一些比较低优先级的任务例如network I/O 的工作就放到rIC 去处理。不过React core team 发现rIC 有一些比较不稳定的问题,首先是浏览器的支援度,再来是他们发现rIC 的触发频率其实是不稳定的,比如说当切换tab 的时后有机会让前一个tab 的rIC 被触发的机会降低,所以React 其实有自己实作一个叫react-scheduler 的package,除了实作rIC 的polyfill 以外也做了一些客制化的调整,它的任务便是调整任务的优先级,让高优先级的任务会优先进入reconciler 的阶段。
这样的方式看似美好,其实存在一个巨大的问题,就是render phase 的这些任务没办法被拆分(这边是指fiber 架构以前),react 会同步的遍历component tree (像左下方这段code 一样,执行的结果会形成一个call stack,React 需要等到这个call stack 清空后(也就是所有function 都执行且return 后)才有办法做下一件事)

另外这样的方式如果是component tree 层级比较深得时候也会让call stack 变的非常肥大,让空间复杂度大大提升。
rIC 跟rAF 虽然强大,但会因为以上这个特性受到一些限制:
- 在前面提过rIC 跟rAF 执行耗时的工作都有机会延迟下一帧的执行
- rIC 跟rAF 其实可以让开发者自己控制timeout 或者是足够的时间超过一个标准才执行任务,不过能做到这点的前提是任务要可以拆分,这样在下一帧才知道要从何继续,这以目前的call stack 架构是无法做到的。
看来React 有必要改变架构,让tree traversal 这个过程变得可以暂停或继续,并且防止call stack 不停的增长。也因此才有了标题提到的React Fiber 将原来的stack 架构改为使用Linked List 架构来遍历component tree 并执行reconciliation。
Fiber Linked List traversal
接下来就来看看React Fiber 架构下的linked list traversal 演算法是怎么运作的,首先要先知道三个关于fiber node 之间relationship 的名词— child、 sibling、 return。child 就是子节点,sibling 则是兄弟节点,而return 则指向父节点,这个演算法的特点是每个节点都只会有各一个child、sibling 与return 。
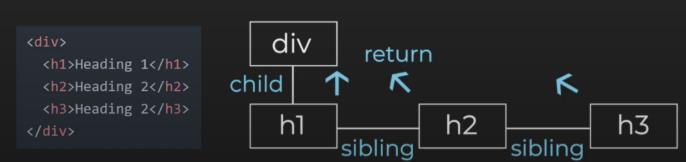
以上图为例,一般我们会认为div 有三个children,分别是h1、h2 与h3,但在fiber 架构下只会把第一个children 当作child,其他children 则使用child 的sibling 来记录,并且透过return 指回parent node。
How React Process A Fiber Tree ?
现在我们知道fiber node 之间的relationship 了,那React 在fiber 架构下究竟是如何遍历一个fiber tree 的呢?
有以下两个规则:
- 深度优先搜寻(DFS)
- child -> 自身-> sibling
这边直接举例可能会比较好懂
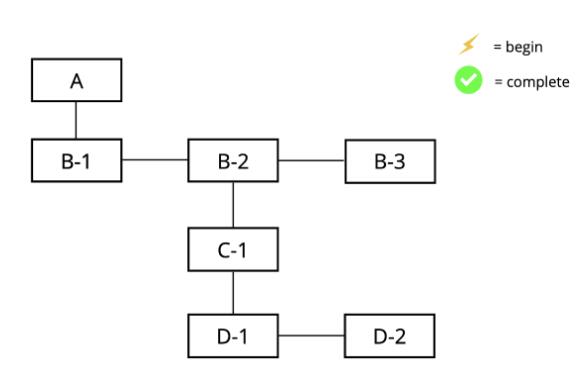
这个component tree 的架构是最上层有一个A 节点,A 节点下有三个children B-1、B-2 与B-3,其中B-2 下层还有子节点,以此类推。在上图中节点间的关系是以刚刚介绍过的fiber relationship 连结在一起的,因此我们可以把上图看作是一个「Fiber Tree」。
React 在遍历fiber tree 的时候,会有「begin」与「complete」两个步骤,并分别会执行一些函式。以走访树状结构来说,我们必须先「begin」父层元件才能接着走访到它的子元件,「complete」子元件后才能回到父元件并且「complete」这个父元件。前面有提到fiber tree 的traversal 会是DFS,并且顺序是Child -> 自身-> Sibling,以上图来说,如果黄色闪电代表begin,绿色勾勾代表complete 的话,整个走访Fiber Tree 的过程会是这样的。
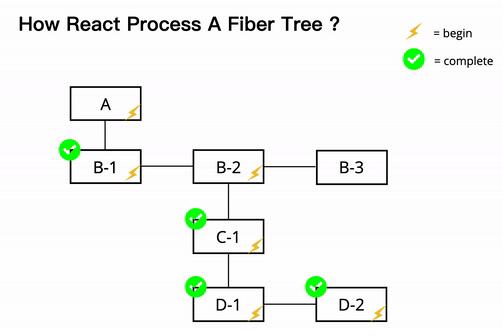
这个遍历树状结构的过程是透过在React source code 中被称作「workLoop」的while 回圈实现的,而非以往recursion 的方式

这么做的好处是当我们每次执行工作(work) 并遍历fiber tree 的节点时就不会导致call stack 不停的增长,linked list 的结构也让我们可以记住目前执行到哪一个节点,让整个过程可以暂停与继续。
Overview of fiber reconciler algorithm
前面已经多次提及Fiber Reconciler 有两个阶段:render phase 与commit phase,而刚刚的段落都是聚焦在render phase,探讨react 如何遍历fiber tree 并得出需要改变的DOM 节点,现在我们来跑一次完整的reconciler 流程并且做一个总结,看看React 在render phase 与commit phase 到底都做了哪些工作,并对整个reconciler 流程有初步的认知。
不过在这之前需要先介绍一些先备知识:
Pre-required knowledge — Current & Work In Progress Tree
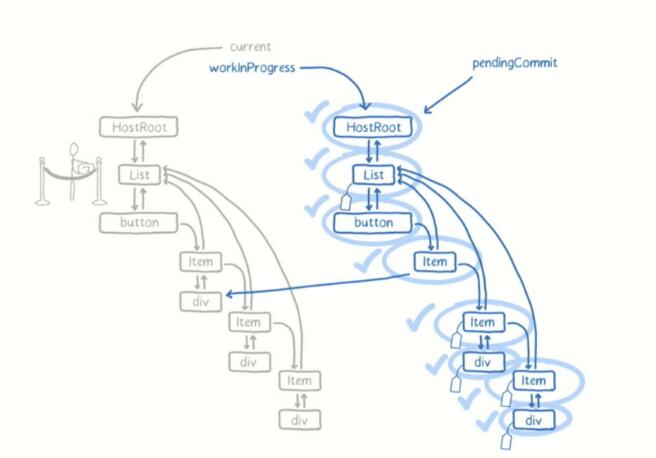
React 在第一次render 时会按照前述从JSX 转换成React Element,再接着形成一个fiber tree,而在之后如果有state 更新等事件需要经过reconciler diff 演算法得知要更新的节点时会建立一个workInProgress 的fiber tree ,react 会把这个workInProgress tree 与原本的current tree 做diff 比较,得出要执行的side effect, 等workInProgress tree 完成后就会把他替换成current tree。
前面提过的React 的workLoop 其实就是一个创建workInProgress tree 的过程。
Pre-required knowledge — Side Effect
刚刚有提到workInProgress tree 会与原本的current tree 做diff 比较,得出要执行的「 side effect」,不知道大家对于side effect 这个词有没有感到疑惑,到底什么是side effect?
以React 来说主要的side effect 有两种:
- DOM 操作
- calling lifecycle method
这些side effect 会在reconciler 的commit phase 以「同步」的方式执行
我们已经知道fiber 其实就是一个javascript 的object,在fiber 里面其实有一个叫做effectTag 的property 来纪录这个节点需要执行哪些side effect ,然后会放入由React 定义好的effect tag 常数
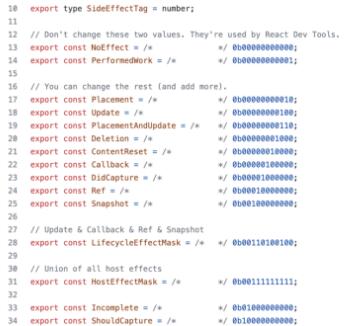
Pre-required knowledge — Effect List
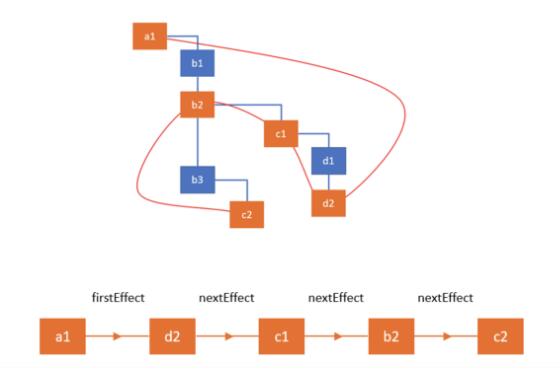
在workInProgress tree 形成之后且与current tree 进行diff 比较后,fiber tree 中的几个需要执行side effect 的节点(记录于effectTag property)间会建立一条单向链结串列结构的effect list,未来要执行这些side effects 的时候就可以直接traverse 这个链结串列而不用再遍历整个fiber tree 找出哪些fiber nodes 需要执行side effect。
Run through the process
具备先备知识后就可以来跑跑看整个reconciler 的流程啰!
在第一次页面渲染时会透过开发者撰写的JSX 语法转换成react elements,再转换成fiber nodes,并形成一个fiber tree。
后来假设component 的state 发生改变,导致重新re-render,就会重新跑一次刚刚的流程,不同的是这次会由带有side effects 的fiber nodes 形成workInProgress tree,并与current fiber tree 做diff 比较得出需要执行的side effects 列表,也就是effect list,并将workInProgress tree 替换成current tree。
以上这些步骤都是在render phase 以非同步的方式执行。
另外在render phase 也会执行一些React 提供的lifecycle method (如上图),不过因为这些lifecycle method 是在render phase 以非同步的方式执行,因此应该尽量避免写一些会造成side effect 的操作,例如说DOM 元件的操作,以免产生一些非预期的结果。
我们可以把render phase 的主要目的想成需要产出
- 一个fiber tree
- 一个effect list
产出fiber tree 与effect list 后,render phase 的工作到这里就差不多告一段落了,接下来就轮到commit phase 了。React 在render phase 的时候就已经建立出了一个单向链结串列结构的effect list,在commit phase 的时候会「同步的」遍历这个effect list 并且执行对应的side effects。
这个阶段必须要是要是同步的原因是「更新真实的DOM 节点」这个操作需要一气呵成不能中断,否则会造成使用者视觉上的不连贯。所以可以归纳出在render phase 的改变使用者是看不到的,必须等到commit phase 才会看到画面产生实际的改变。
而React component 中的一些life cycle method 则会在commit 阶段执行,这边的life cycle method 就可以执行一些side effect 例如DOM 操作或是subscription…等等。
What fiber brings for the future ?
大家一定都听过react fiber 是react 未来很多features 可以实现的基础,最知名的应该就是concurrent mode 的asynchronous rendering 与suspense 的data fetching,而这些features 看起来都已经是未来必定会实现的功能了,今天就不花篇幅说明这些。
我在网路上看到有人提出一点可能性,自己觉得蛮有意思的,在今天的内容中我们可以归纳出react fiber reconciler 的最终目标其实就是得到commit phase 要执行的effect list,中间的过程(render phase)既然是可以拆分且非同步执行的,那是不是有机会透过多个web worker + react reconciler 达到平行执行来提升整体效能?这个可能性我认为还蛮值得去思考与期待的。(当然web worker 不是所有效能问题的银弹,还有太多太多问题需要考虑,这边只是提出一个可能性让大家思考而已。)
结论
我一直深信花时间去了解更底层的实践过程,对于一项技术的掌握度是会大幅提升的。身为React 开发者,我们一定都听过React 16 时改为使用fiber 架构,但也许不是每个人都会去研究它背后运作的原理。当我自己花时间去理解后,顿时有种打通任督二脉的感觉,瞬间理解之前令我感到困惑的许多眉眉角角,也对于React 未来的演进有了些方向与期待。当然要透过一篇文章就介绍完React Fiber 还是太困难了,这边只能做个简单的Intro,希望有帮助到正在阅读的你,最后也非常推荐有兴趣与耐心的朋友一起去探索看看React 的Source Code 喔!
来自:https://medium.com/starbugs/react-React 開發者一定要知道的底層機制-react-fiber-c3ccd3b047a1
本文内容仅供个人学习、研究或参考使用,不构成任何形式的决策建议、专业指导或法律依据。未经授权,禁止任何单位或个人以商业售卖、虚假宣传、侵权传播等非学习研究目的使用本文内容。如需分享或转载,请保留原文来源信息,不得篡改、删减内容或侵犯相关权益。感谢您的理解与支持!