js字典树算法_Trie树(字典树)实现与应用
Trie树(来自单词retrieval),又称前缀字,单词查找树,字典树,是一种树形结构,是一种哈希树的变种,是一种用于快速检索的多叉树结构。
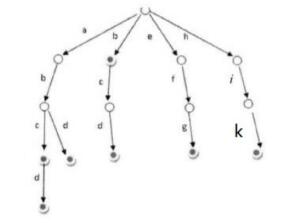
字典树是处理字符串常见的一种树形数据结构,其优点是利用字符串的公共前缀来节约存储空间,比如加入‘abc’,‘abcd’,‘abd’,‘bcd’,‘efg’,‘hik’之后,其结构应该如下图所示:
假设我有一个题目,要求设计一个存储至少500W量级英文单词的数据结构,需要满足下面两个需求:
1.当有新的单词加入时,需要判断是否在已经存储的单词中,如果不存在则直接插入
2.来了一个单词的前缀,统计一下存储的单词中有多少个单词前缀是和该单词前缀相同
下面我们开始来实现这个数据结构:
//字典树
var triNode = function(key){
this.key = key;
this.son = [];
this.isWord = false;//用于单词标记
}
var tree = function(){
this.root = new triNode(null);
}
tree.prototype={
insertData:function(stringData){
//用于外部调用插入,目的是从根节点开始插入
this.insert(stringData,this.root)
},
insert:function(stringData,node){
//用于内部自身递归调用,层层判断是否存在或是否要插入
if(stringData==''){
//字符串为空,直接返回结束
return;
}
//获取子节点
var son = this.getSon(node);
var haveData = null;
//声明一个变量用来存储字符串第一个字符和子节点相同的节点,方便后续节点递归遍历
for(var i in son){
if(son[i].key==stringData[0]){
haveData = son[i]
}
}
if(haveData){
if(stringData.length==1){
haveData.isWord = true;
}
//havaData存在说明在子节点找到了,然后进行深入节点查找
this.insert(stringData.substring(1),haveData)
}else{
if(son.length==0){
//如果子节点为空,则直接插入
var node = new triNode(stringData[0]);
son.push(node);
if(stringData.length==1){
node.isWord = true;
}
//插入完毕后将后续字符串继续插入
this.insert(stringData.substring(1),node);
}else{
var node = new triNode(stringData[0]);
//将子节点的key进行排序插入,方便后续进行二分法查找,加快查找效率
var vlPosition = 0;
for(var j in son){
if(son[j].key<stringData[0]){
vlPosition++;
}
}
if(stringData.length==1){
node.isWord = true;
}
//子节点插入
son.splice(vlPosition,0,node);
//插入完毕后将后续字符串继续插入
this.insert(stringData.substring(1),node);
}
}
},
justContentData:function(stringData){
if(stringData==''){
return 0
}else{
return this.justContent(stringData,this.root);
}
},
justContent:function(stringData,node){
if(stringData==''){
//字符串为空,直接返回结束
return 1;
}
var son = this.getSon(node);
var havaData = null;
for(var i in son){
if(son[i].key==stringData[0]){
havaData = son[i];
}
}
if(havaData){
return this.justContent(stringData.substring(1),havaData)
}else{
return 0
}
},
countBeforeData:function(stringData){
if(stringData==''){
return 0;
}
var node = this.searchBeforeNode(stringData,this.root);
if(!node){
return 0;
}
return this.countBefore(node,0);
},
searchBeforeNode:function(stringData,node){
if(stringData==''){
//字符串为空,直接返回结束
return node;
}
var son = this.getSon(node);
var havaData = null;
for(var i in son){
if(son[i].key==stringData[0]){
havaData = son[i];
}
}
if(havaData){
return this.searchBeforeNode(stringData.substring(1),havaData)
}else{
return null
}
},
countBefore:function(node,num){
if(node.isWord){
num++;
}
var son = this.getSon(node);
var havaData = null;
for(var i in son){
num=this.countBefore(son[i],num);
}
return num;
},
getSon:function(node){
//获取子节点
return node.son;
}
}
var msd = new tree()
//插入数据
msd.insertData("hello");
msd.insertData("helo");
msd.insertData("healo");
msd.insertData("haslo");
//前缀数量
msd.countBeforeData("ha");以上便是完整的一个解决上述问题的代码。字典树的一个常用场景有代码补全,输入框单词提示等。
Trie的核心思想是空间换时间。利用字符串的公共前缀来降低查询时间的开销以达到提高效率的目的。
Trie树也有它的缺点, 假定我们只对字母与数字进行处理,那么每个节点至少有52+10个子节点。为了节省内存,我们可以用链表或数组。在JS中我们直接用数组,因为JS的数组是动态的,自带优化。
来自:https://www.oecom.cn/js-use-trie/
本文内容仅供个人学习、研究或参考使用,不构成任何形式的决策建议、专业指导或法律依据。未经授权,禁止任何单位或个人以商业售卖、虚假宣传、侵权传播等非学习研究目的使用本文内容。如需分享或转载,请保留原文来源信息,不得篡改、删减内容或侵犯相关权益。感谢您的理解与支持!

