精读《V8 引擎 Lazy Parsing》
1. 引言
本周精读的文章是 V8 引擎 Lazy Parsing,看看 V8 引擎为了优化性能,做了怎样的尝试吧!这篇文章介绍的优化技术叫 preparser,是通过跳过不必要函数编译的方式优化性能。
2. 概述 & 精读
解析 Js 发生在网页运行的关键路径上,因此加速对 JS 的解析,就可以加速网页运行效率。
然而并不是所有 Js 都需要在初始化时就被执行,因此也不需要在初始化时就解析所有的 Js!因为编译 Js 会带来三个成本问题:
- 编译不必要的代码会占用 CPU 资源。
- 在 GC 前会占用不必要的内存空间。
- 编译后的代码会缓存在磁盘,占用磁盘空间。
因此所有主流浏览器都实现了 Lazy Parsing(延迟解析),它会将不必要的函数进行预解析,也就是只解析出外部函数需要的内容,而全量解析在调用这个函数时才发生。
预解析的挑战
本来预解析也不难,因为只要判断一个函数是否会立即执行就可以了,只有立即执行的函数才需要被完全解析。
使得预解析变复杂的是变量分配问题。原文通过了堆栈调用的例子说明原因:
Js 代码的执行在堆栈上完成,比如下面这个函数:
function f(a, b) {
const c = a + b;
return c;
}
function g() {
return f(1, 2);
// The return instruction pointer of `f` now points here
// (because when `f` `return`s, it returns here).
}这段函数的调用堆栈如下:

首先是全局 This globalThis,然后执行到函数 f,再对 a b 进行赋值。在执行 f 函数时,通过 <rip g>(return instruction pointer) 保存 g 堆栈状态,再保存堆栈跳出后返回位置的指针 <save fp>(frame pointer),最后对变量 c 赋值。
这看上去没有问题,只要将值存在堆栈就搞定了。但是将变量定义到函数内部就不一样了:
function make_f(d) {
// ← declaration of `d`
return function inner(a, b) {
const c = a + b + d; // ← reference to `d`
return c;
};
}
const f = make_f(10);
function g() {
return f(1, 2);
}将变量 d 申明在函数 make_f 中,且在返回函数 inner 中用到了 d。那么函数的调用栈就变成了这样:
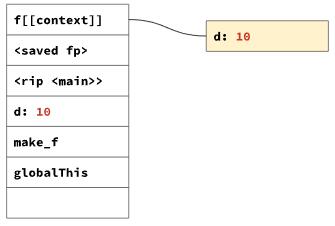
需要创建一个 context 存储函数 f 中变量 d 的值。
也就是说,如果一个在函数内部定义的变量被子 Scope 使用时,Js 引擎需要识别这种情况,并将这个变量值存储在 context 中。
所以对于函数定义的每一个入参,我们需要知道其是否会被子函数引用。也就是说,在 preparser 阶段,我们只要少能分析出哪些变量被内部函数引用了。
难以分辨的引用
预处理器中跟踪变量的申明与引用很复杂,因为 Js 的语法导致了无法从部分表达式推断含义,比如下面的函数:
function f(d) {
function g() {
const a = ({ d }我们不清楚第三行的 d 到底是不是指代第一行的 d。它可能是:
function f(d) {
function g() {
const a = ({ d } = { d: 42 });
return a;
}
return g;
}也可能只是一个自定义函数参数,与上面的 d 无关:
function f(d) {
function g() {
const a = ({ d }) => d;
return a;
}
return [d, g];
}惰性 parse
在执行函数时,只会将最外层执行的函数完全编译并生成 AST,而对内部模块只进行 preparser。
// This is the top-level scope.
function outer() {
// preparsed
function inner() {
// preparsed
}
}
outer(); // Fully parses and compiles `outer`, but not `inner`.为了允许惰性编译函数,上下文指针指向了 ScopeInfo 的对象(从代码中可以看到,ScopeInfo 包含上下文信息,比如当前上下文是否有函数名,是否在一个函数内等等),当编译内部函数时,可以利用 ScopeInfo 继续编译子函数。
但是为了判断惰性编译函数自身是否需要一个上下文,我们需要再次解析内部的函数:比如我们需要知道某个子函数是否对外层函数定义的变量有所引用。
这样就会产生递归遍历:

由于代码总会包含一些嵌套,而编译工具更会产生 IIFE(立即调用函数) 这种多层嵌套的表达式,使得递归性能比较差。
而下面有一种办法可以将时间复杂度简化为线性:将变量分配的位置序列化为一个密集的数组,当惰性解析函数时,变量会按照原先的顺序重新创建,这样就不需要因为子函数可能引用外层定义变量的原因,对所有子函数进行递归惰性解析了。
按照这种方式优化后的时间复杂度是线性的:

针对模块化打包的优化
由于现代代码几乎都是模块化编写的,构建起在打包时会将模块化代码封装在 IIFE(立即调用的闭包)中,以保证模拟模块化环境运行。比如 (function(){....})()。
这些代码看似在函数中应该惰性编译,但其实这些模块化代码从一开始就要被编译,否则反而会影响性能,因此 V8 有两种机制识别这些可能被立即调用的函数:
- 如果函数是带括号的,比如 (function(){...}),就假设它会被立即调用。
- 从 V8 v5.7 / Chrome 57 开始,还会识别 uglifyJS 的 !function(){...}(), function(){...}(), function(){...}() 这种模式。
然而在浏览器引擎解析环境比较复杂,很难对函数进行完整字符串匹配,因此只能对函数头进行简单判断。所以对于下面这种匿名函数的行为,浏览器是不识别的:
// pre-parser
function run(func) {
func()
}
run(function(){}) // 在这执行它,进行 full parser上面的代码看上去没毛病,但由于浏览器只检测被括号括住的函数,因此这个函数不被认为是立即执行函数,因此在后续执行时会被重复 full-parse。
也有一些代码辅助转换工具帮助 V8 正确识别,比如 optimize-js,会将代码做如下转换。
转换前:
!function (){}()
function runIt(fun){ fun() }
runIt(function (){})转换后:
!(function (){})()
function runIt(fun){ fun() }
runIt((function (){}))然而在 V8 v7.5+ 已经很大程度解决了这个问题,因此现在其实不需要使用 optimize-js 这种库了~
4. 总结
JS 解析引擎在性能优化做了不少工作,但同时也要应对代码编译器产生的特殊 IIFE 闭包,防止对这种立即执行闭包进行重复 parser。
最后,不要试图总是将函数用括号括起来,因为这样会导致惰性编译的特性无法启用。
讨论地址是:精读《V8 引擎 Lazy Parsing》 · Issue #148 · dt-fe/weekly
本文内容仅供个人学习、研究或参考使用,不构成任何形式的决策建议、专业指导或法律依据。未经授权,禁止任何单位或个人以商业售卖、虚假宣传、侵权传播等非学习研究目的使用本文内容。如需分享或转载,请保留原文来源信息,不得篡改、删减内容或侵犯相关权益。感谢您的理解与支持!
