带你了解字符编码的前世今生
1946 计算机诞生
1946 年,世界第一台计算机诞生了。计算机由硬件和系统软件组成,它最基本的功能就是存储、表示与处理信息。通俗地说,信息其实就是由各种各样的字符组成,比如英文字母、汉字以及其他国家的语言等。那么计算机如何才能表示这些各种各样的字符呢?
于是有一群人想到,我们可以用8个晶体管的“通”或“断”组合出一些不同的状态,来表示信息。“通”用 1 表示,“断”用 0 表示,这样一个由值 0 和 1 组成的长度为 8 的位序列,就代表着一个字节,八个二进制位可以组合出 256 种状态,这样一个字节就可以表示 256 种字符。
1967 ASCII
计算机最先只在美国使用,他们把所有的空格、标点符号、数字、大小写字母分别用单个字节表示,一直编到了第128个,这样计算机就可以用不同字节来存储英语的文字了,于是美国制定了一套 ASCII 编码标准,用来规定这种英语字符与二进制位之间的关系。
这种方式就是用一个唯一的单字节大小的整数值来表示每个字符。ASCII 码一共规定了 128 个字符的编码,这 128 个符号,只占用了一个字节的后面 7 位,最前面的一位统一规定为 0。比如空格 SPACE 是 32(二进制00100000),大写的字母A是65(二进制01000001)。
EASCII
后来,世界各地都开始使用计算机,128 个字符对于英语字符确实够用了,但用来表示其他语言就有些捉襟见肘了。比如法语中,字母上方有注音符号,于是,一些欧洲国家就决定,利用字节中闲置的最高位编入新的符号。这样一来,这些欧洲国家的编码体系,可以表示最多 256 个字符了。因此 EASCII(Extended ASCII,延伸美国标准信息交换码)应运而生。下图是 EASCII 码比 ASCII 码扩充出来的符号包括表格符号、计算符号、希腊字母和特殊的拉丁符号
1981 GB2312
但是等计算机发展到中国,256种符号用来表示我们这10万左右的汉字就远远不够了,单个字节不够,我们就用两个字节组合起来表示呀,于是我们规定,一个小于 127 的字符的意义与原来相同,但两个大于 127 的字符连在一起时,就表示一个汉字,前面的一个字节(称之为高字节)从 0xA1 用到 0xF7,后面一个字节(称之为低字节)从 0xA1 用到 0Xfe,这样我们可以组合出大约 7000 多个简体汉字了。
于是 1981 年,国家标准化管理委员会正式制订了中华人民共和国国家标准简体中文字符集,全称《信息交换用汉字编码字符集·基本集》,项目代号为 GB 2312。
1984 BIG5
但是又考虑到港澳台同胞使用的繁体字并没有收录到GB2312编码,于是信息工业策进会在1984年与台湾13家厂商签定“16位个人电脑套装软件合作开发(BIG-5)计划”,开始编写并推出了BIG5标准。
1991 Unicode
随着计算机的飞速发展,各个国家都开始制定自己的编码标准,这样导致了国家之间谁也不懂别人的编码,不支持别人的编码,这时候要是将全世界所有的字符包含在一个集合里,有一个统一的字符集就好了,就不会再有乱码的问题。
于是有两个组织都开始研究这件事,1984 年 ISO/IEC 小组成立,随后 1988 年统一码联盟成立,后来他们发现各自在做相同的工作,于是两个组织决定合并字符集。国际组织因此发行了一个全球统一编码表,把全球各国文字都统一在一个编码标准里,名为 Unicode。1991 年,两个组织共同的工作成果 Unicode 1.0 正式发布,不过 Unicode 1.0 并不包含 CJK 字符(即中日韩)。
1993 UCS
1993 年,ISO/IEC 小组发表了 ISO/IEC 10646 标准,ISO 10646 标准中定义的字符集为 UCS。UCS 是一个超大的字符集,它有两种编码方案:UCS-2 和UCS-4,Unicode 默认以 UCS-2 编码。
我们可以把 Unicode 看作是一个标准或组织,而 UCS 就是一个字符集,那么 UCS 在网络中的传输标准就是 UTF 。UTF 是Unicode Transformation Format 的缩写,中文译作 Unicode 转换格式。UTF-8 就是在互联网上使用最广的一种 Unicode 的实现方式。其他实现方式还包括 UTF-16(字符用两个字节或四个字节表示)和 UTF-32(字符用四个字节表示)。
UTF-32
UTF-32的编码方法是,每个码点使用四个字节表示,字节内容一一对应码点。比如:
U+0000 = 0x0000 0000
U+597D = 0x0000 597D
UTF-32 的优点在于,转换简单直观,查找效率高,时间复杂度只为 O(1)。缺点在于浪费空间,同样内容的英语文本,它会比 ASCII 编码大四倍。所以不推荐使用这种编码方法,HTML 5 标准就明文规定,网页不得编码成 UTF-32。
UTF-8
UTF-8 最大的一个特点,就是它是一种变长的编码方式。它使用 1~4 个字节表示一个符号,根据不同的符号而变化字节长度。这样对于存储来说并没有造成极大的浪费,节省了许多空间。
UTF-8 的编码规则有二条:
1)对于单字节的符号,字节的第一位设为 0,后面 7 位为这个符号的 Unicode 码。因此对于英语字母,UTF-8 编码和 ASCII 码是相同的。
2)对于 n 字节的符号(n > 1),第一个字节的前n 位都设为 1,第 n + 1 位设为 0,后面字节的前两位一律设为 10。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码。
如此一来:
- 128 个 ASCII 字符只需一个字节编码(Unicode 范围由 U+0000 至 U+007F)
- 拉丁文、希腊文、西里尔字母、亚美尼亚语、希伯来文、阿拉伯文、叙利亚文及它拿字母需要二个字节编码(Unicode 范围由 U+0080 至 U+07FF)
- 大部分国家的常用字(包括中文)使用三个字节编码
- 其他极少使用的生僻字符使用四字节编码
例如,希伯来语字母 aleph(א)的 Unicode 代码是 U+05D0,按照以下方法改成 UTF-8:
- 它属于 U+0080 到 U+07FF 区域,说明它使用双字节,110yyyyy 10zzzzzz.
- 十六进制的 0x05D0 换算成二进制就是 101-1101-0000.
- 这 11 位数按顺序放入"y"部分和"z"部分:11010111 10010000.
- 最后结果就是双字节,用十六进制写起来就是 0xD7 0x90,这就是字符 aleph(א)的 UTF-8 编码。
UTF-16
UTF-16 编码介于 UTF-32 与 UTF-8 之间,同时结合了定长和变长两种编码方法的特点。长度为 2 个字节(基本平面:U+0000 到 U+FFFF)或 4 个字节(辅助平面:U+010000 到 U+10FFFF)。128 个 ASCII 字符需两个字节编码,而其他字符使用四个字节编码。
当我们要转成 UTF-16 的时候,首先区分这是基本平面字符,还是辅助平面字符。如果是前者,直接将码点转为对应的十六进制形式,长度为两字节。比如 U+597D = 0x597D。如果是辅助平面字符,则根据转码公式进行计算。
作为逻辑意义上的 UTF-16 编码(码元序列),由于历史的原因,在映射为物理意义上的字节序列时,分为 UTF-16BE( Big Endian )、UTF-16LE( Little Endian )两种情况。比如,“ABC” 这三个字符的 UTF-16 编码(码元序列)为:00 41 00 42 00 43;其对应的各种字节序列如下:
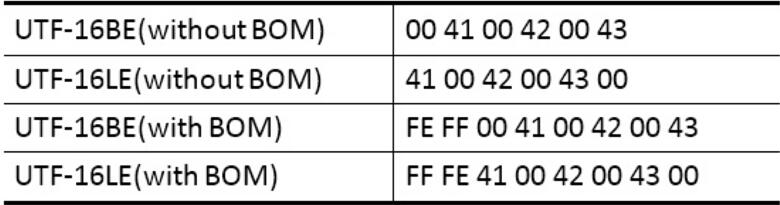
Windows 平台下的 UTF-16 编码(即上述的FF FE 41 00 42 00 43 00) 默认为带有 BOM 的小端序(即Little Endian with BOM)。
Little endian 和 Big endian
Unicode 规范定义,每一个文件的最前面分别加入一个表示编码顺序的字符,这个字符的名字叫做"零宽度非换行空格"(zero width no-break space),用 FEFF 表示。这正好是两个字节,而且 FF 比 FE 大 1。
如果一个文本文件的头两个字节是 FE FF,就表示该文件采用大头方式;如果头两个字节是 FF FE,就表示该文件采用小头方式。
BOM (Byte order Mark)
Unicode 规范中推荐的标记字节顺序的方法是 BOM。它出现在文本文件头部,用于标识文件是采用哪种格式的编码。
1993 GB13000
1993 年,包含 CJK 的 Unicode 1.1 已经发布了,于是在同一年,中国大陆制定了 GB13000.1-93 国家编码标准(简称 GB13000)。此标准等同于 ISO/IEC 10646.1:1993 和 Unicode 1.1。
1995 GBK
随着个人计算机在中国的流行,微软开始意识到中国是一个巨大的市场,于是 1995 年,微软利用了 GB2312 中未使用的编码空间,收录了 GB13000 中的所有字符制定了汉字内码扩展规范 GBK。所以 GBK 是向下完全兼容 GB2312 的。
GBK 共收入 21886 个汉字和图形符号,包括:
- GB 2312 中的全部汉字、非汉字符号。
- BIG5 中的全部汉字。
- 与 ISO 10646 相应的国家标准 GB 13000 中的其它 CJK 汉字,以上合计 20902 个汉字。
- 其它汉字、部首、符号,共计 984 个。
GBK 采用双字节表示,总体编码范围为 8140-FEFE 之间,首字节在 81-FE 之间,尾字节在 40-FE 之间,剔除 XX7F 一条线。GBK 编码区分三部分:汉字区、图形符号区、用户自定义区。
2000 GB18030
考虑到 GBK 只包含了大部分的汉字和繁体字等,我们的少数民族的自己的汉字并没有考虑在内,于是在 2000 年,电子工业标准化研究所起草了 GB18030 标准,项目代号 “GB 18030-2000”,全称《信息技术-信息交换用汉字编码字符集-基本集的扩充》。该标准收录了27484个汉字,同时还收录了藏文、蒙文、维吾尔文等主要的少数民族文字。
本文内容仅供个人学习、研究或参考使用,不构成任何形式的决策建议、专业指导或法律依据。未经授权,禁止任何单位或个人以商业售卖、虚假宣传、侵权传播等非学习研究目的使用本文内容。如需分享或转载,请保留原文来源信息,不得篡改、删减内容或侵犯相关权益。感谢您的理解与支持!


