理解Javascript的正则表达式
正文
相信很多人第一次见到正则表达式的第一印象都是懵逼的,对新手而言一个正则表达式就是一串毫无意义的字符串,让人摸不着头脑。但正则表达式是个非常有用的特性,不管是Javascript、PHP、Java还是Python都有正则表达式。俨然正则表达式已经发展成了一门小语言。作为编程语言的一部分,它不想变量,函数,对象这种概念那么容易理解。很多人对于正则表达式的理解都是基于简单的匹配,等到业务中用到完全靠从网上copy来解决问题。不得不说,随着各种开源技术社区的发展,靠copy的确能解决业务中绝大多数的问题,但作为一名有追求的程序员,是绝对不会让自己仅仅依靠Ctrl C + Ctrl V来编程的。本文基于Javascript的正则表达式,结合笔者个人的思考和社区内一些优秀正则表达式文章来对正则表达式进行讲解。
Javascrip中的正则表达式使用方法
简单介绍下,在Javascript中使用正则表达式有两种方式:
构造函数:使用内置的RegExp构造函数;
字面量:使用双斜杠(//);
使用构造函数:
var regexConst = new RegExp('abc');使用双斜杠:
var regexLiteral = /abc/;匹配方法
Javascript中的正则表达式对象主要有两个方法,test和exec:
test()方法接受一个参数,这个参数是用来与正则表达式匹配的字符串,如下例子:
var regex = /hello/;
var str = 'hello world';
var result = regex.test(str);
console.log(result);
// returns trueexec()方法在一个指定字符串中执行一个搜索匹配。返回一个结果数组或 null。
var regex = /hello/;
var str = 'hello world';
var result = regex.exec(str);
console.log(result);
// returns [ 'hello', index: 0, input: 'hello world', groups: undefined ]
// 匹配失败会返回null
// 'hello' 待匹配的字符串
// index: 正则表达式开始匹配的位置
// input: 原始字符串下文都用test()方法来进行测试。
标志
标志是用来表示搜索字符串范围的一个参数,主要有6个标志:
| 标志 | 描述 |
|---|---|
| g | 全局搜索。 |
| i | 不区分大小写搜索。 |
| m | 多行搜索。 |
| s | 允许 . 匹配换行符。 |
| u | 使用unicode码的模式进行匹配。 |
| y | 执行“粘性”搜索,匹配从目标字符串的当前位置开始,可以使用y标志。 |
双斜杠语法:
var re = /pattern/flags;构造函数语法:
var re = new RegExp("pattern", "flags");看下实例:
var reg1 = /abc/gi;
var reg2 = new RegExp("abc", "gi");
var str = 'ABC';
console.log(reg1.test(str)); // true
console.log(reg2.test(str)); // true正则表达式的思考
正则表达式是对字符串进行匹配的一种模式。
请记住,正则表达式是对字符串的操作,所以一般具有字符串类型的编程语言都会有正则表达式。
对于字符串而言,是由两部分构成的:内容和位置。
比如一个字符串:
'hello World';它的内容就是:
'h', 'e', 'l', 'l', 'o', ' ', 'W', 'o', 'r', 'l', 'd'如上字符串中每一个独立的字母就是这个字符串的内容,而位置指的是:
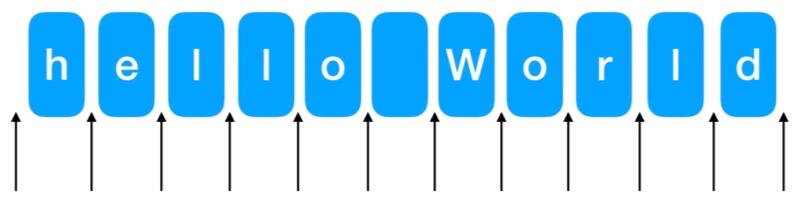
位置所指就是相邻字符之间的位置,也就是上图中箭头的位置。
匹配内容相比匹配位置来说更为复杂,先看下简单的匹配方式:
简单匹配
最简单的匹配方式就是完整的去匹配一个字符串:
var regex = /hello/;
console.log(regex.test('hello world'));
// true复杂匹配
正则表达式中有很多特殊字符用来匹配字符串,解决的就是匹配多少(按位置匹配)和匹配谁(按内容匹配)的问题。我们先来看下用来决定匹配谁的一些特殊字符:
匹配内容
简单的特殊字符
简单的匹配内容有如下的特殊字符:
[xyz] :字符集,用来匹配方括号中的任意一个字符,比如:
var regex = /[bt]ear/;
console.log(regex.test('tear'));
// returns true
console.log(regex.test('bear'));
// return true
console.log(regex.test('fear'));
// return false注意:除了特殊字符^外,其它所有的特殊字符在字符集(方括号中)都会失去它的特殊含义。
[^xyz]:这也是个字符集,和上面字符集不同的事,它用来匹配所有不在方括号中的字符。比如:
var regex = /[^bt]ear/;
console.log(regex.test('tear'));
// returns false
console.log(regex.test('bear'));
// return false
console.log(regex.test('fear'));
// return true针对小写字母,大写字母和数字这三种非常常用的字符,还提供了比较简便的写法:
\d:相当于[0-9],匹配数字字符。
\D:相当于[^0-9],匹配非数字的字符。
\w:相当于[a-zA-Z0–9_],匹配数字、小写字母、大写字母和下划线。
\W:相当于[^A-Za-z0-9_],匹配非数字、非小写字母、非大写字母和非下划线。
[a-z]:假如我们想匹配所有的字母,一个笨办法就是将所有的字母都写到方括号里,但很明这种实现很不优雅,不易读而且很容易遗漏字母。这里有一种更简单的实现方案,就是指定字符范围,比如[a-h]就是匹配字母a到字母h之间所有的字母,除了小写字母还可以匹配数字和大写字母,[0-9]匹配0到9之间的数字,[A-Z]匹配A到Z之间所有的大写字母。比如:
var regex = /[a-z0-9A-Z]ear/;
console.log(regex.test('fear'));
// returns true
console.log(regex.test('tear'));
// returns true
console.log(regex.test('1ear'));
// returns true
console.log(regex.test('Tear'));
// returns truex|y:匹配x或是y。比如:
var regex = /(green|red) apple/;
console.log(regex.test('green apple'));
// true
console.log(regex.test('red apple'));
// true
console.log(regex.test('blue apple'));
// false.: 匹配除换行符之外的任何单个字符,如果标志中有s则也会匹配换行符例子:
var regex = /.n/ ;
console.log(regex.test('an'));
// true
console.log(regex.test('no'));
// false
console.log(regex.test('on'));
// true
console.log(regex.test(`
n`));
// false
console.log(/.n/s.test(`
n`)); // 注意这里的正则
// true\:这个特殊字符是用来转义的,比如我们想匹配方括号,就可以用\转义,同样相匹配也可以用\转义,比如:
var regex = /\[\]/;
console.log(regex.test('[]')); // true上面的特殊字符都只能匹配某个目标字符串一次,但很多场景下我们需要匹配目标字符串多次,比如我们想匹配无数个a,上面的特殊字符就无法满足我们的需求了,因此匹配内容的特殊字符里还有一部分是用来解决这个问题的:
{n}:匹配大括号之前的字符n次。例子:
var regex = /go{2}d/;
console.log(regex.test('good'));
// true
console.log(regex.test('god'));
// false很好理解,上面的正则相当于/good/。
{n,}:匹配大括号之前的字符至少n次。例子:
var regex = /go{2,}d/;
console.log(regex.test('good'));
// true
console.log(regex.test('goood'));
// true
console.log(regex.test('gooood'));
// true{n,m}:匹配大括号之前的字符至少n次,至多m次。例子:
var regex = /go{1,2}d/;
console.log(regex.test('god'));
// true
console.log(regex.test('good'));
// true
console.log(regex.test('goood'));
// false为了更为方便的使用,还提供了三个比较常用规则更为方便的写法:
*:相当于{0,}。表示前面的字符至少出现0次,也就是出现任意次。
+:相当于{1,}。表示前面的字符至少出现1次。
?:相当于{0,1}。表示前面的字符不出现或是出现1次。
使用以上内容匹配普通的字符已经可以满足需求了,但像换行符、换页符和回车等特殊的符号以上的特殊字符无法满足需求,因此正则表达式还提供了专门用来匹配特殊符号的特殊字符:
\s :匹配一个空白字符,包括空格、制表符、换页符和换行符。看下例子:
var reg = /\s/;
console.log(reg.test(' ')); // true\S:匹配一个非空白字符;
\t:匹配一个水平制表符 。
\n:匹配一个换行符。
\f:匹配一个换页符。
\r:匹配一个回车符。
\v:匹配一个垂直制表符。
\0:匹配 NULL(U+0000)字符。
[\b]:匹配一个退格。
\cX:当X是处于A到Z之间的字符的时候,匹配字符串中的一个控制符。
内容匹配进阶
(x): 匹配x并记住x,括号内的内容被称为捕获组。这个括号里强大的是可以支持子表达式,就是说可以在括号里去写正则,然后作为一个整体去匹配。这里还有一个特殊字符叫\n,这个n和前面换行符不一样,这是个变量指的是数字,用来记录捕获组序号的。例子:
console.log(/(foo)(bar)\1\2/.test('foobarfoobar')); // true
console.log(/(\d)([a-z])\1\2/.test('1a1a')); // true
console.log(/(\d)([a-z])\1\2/.test('1a2a')); // false
console.log(/(\d){2}/.test('12')); // true在正则表达式的替换环节,则要使用像 $1、$2、...、$n 这样的语法,例如,'bar foo'.replace(/(...) (...)/, '$2 $1')。$& 表示整个用于匹配的原字符串。
(?:x):匹配 'x' 但是不记住匹配项。被称为非捕获组。这里的1不会生效,会把它当做普通字符处理。例子:
var regex = /(?:foo)bar\1/;
console.log(regex.test('foobarfoo'));
// false
console.log(regex.test('foobar'));
// false
console.log(regex.test('foobar\1'));
// true匹配位置
再次强调,这里的位置是前面图里箭头的位置。
^:匹配字符串的开始位置,也就是我们前面位置图的第一个箭头的位置。注意和[^xy]中的^区分,两个含义完全不同,看^例子:
var regex = /^g/;
console.log(regex.test('good'));
// true
console.log(regex.test('bad'));
// false
console.log(regex.test('tag'));
// false上面正则的含义即匹配字母g开头的字符串。
$:匹配字符串的结束位置,例子:
var regex = /.com$/;
console.log(regex.test('test@testmail.com'));
// true
console.log(regex.test('test@testmail'));
// false上面正则的含义即匹配以.com为结尾的字符串
\b:匹配一个词的边界。注意匹配的是一个词的边界,这个边界指的是一个词不被另外一个“字”字符跟随的位置或者前面跟其他“字”字符的位置。也就是符合要求的某个位置两边不全是正常字符或不全是特殊符号的。看例子:
console.log(/\bm/.test('moon')); // true 匹配“moon”中的‘m’,\b的左边是空字符串,右边是'm'
console.log(/oo\b/.test('moon')); // false 并不匹配"moon"中的'oo',因为 \b左边上oo,右边是n,全是正常字符
console.log(/oon\b/.test('moon')); // true 匹配"moon"中的'oon',\b左边是oon,右边是空字符串
console.log(/n\b/.test('moon ')); // true 匹配"moon"中的'n',\b左边是n,右边是空格
console.log(/\bm/.test(' moon')); // true 匹配"moon"中的'm',\b左边是空字符串 右边是m
console.log(/\b/.test(' ')); // false 无法匹配空格,\b左边是空格或空字符串,右边是空格或是空字符串,无法满足不全是正常字符或是不全是正常字符这个如果不好理解,可以先看\B,更好理解一点。
\B: 匹配一个非单词边界,和\b相反,也就是说匹配的是左右两边全是正常字符或全是特殊符号的位置。看例子:
console.log(/\B../.test('moon')); // true 匹配'moon'中的'oo' \B左边是m,右边是o
console.log(/\B./.exec(' ')); // true 匹配' '中的' ' \B左边是空字符串,右边是空格' 'x(?!y):仅仅当'x'后面不跟着'y'时匹配'x',这被称为正向否定查找。例子:
var regex = /Red(?!Apple)/;
console.log(regex.test('RedOrange')); // true(?<!y)x:仅仅当'x'前面不是'y'时匹配'x',这被称为反向否定查找。例子:
var regex = /(?<!Red)Apple/;
console.log(regex.test('GreenApple')); // truex(?=)y:匹配'x'仅仅当'x'后面跟着'y'.这种叫做先行断言。例子:
var regex = /Red(?=Apple)/;
console.log(regex.test('RedApple')); // true(?<=y)x:匹配'x'仅仅当'x'前面是'y'.这种叫做后行断言。例子:
var regex = /(?<=Red)Apple/;
console.log(regex.test('RedApple')); // trueJS中可以使用正则表达式的方法
| 方法 | 描述 |
|---|---|
| RegExp.prototype.exec | 一个在字符串中执行查找匹配的RegExp方法,它返回一个数组(未匹配到则返回 null)。 |
| RegExp.prototype.test | 一个在字符串中测试是否匹配的RegExp方法,它返回 true 或 false。 |
| String.prototype.match | 一个在字符串中执行查找匹配的String方法,它返回一个数组,在未匹配到时会返回 null。 |
| String.prototype.matchAll | 一个在字符串中执行查找所有匹配的String方法,它返回一个迭代器(iterator)。 |
| String.prototype.search | 一个在字符串中测试匹配的String方法,它返回匹配到的位置索引,或者在失败时返回-1。 |
| String.prototype.replace | 一个在字符串中执行查找匹配的String方法,并且使用替换字符串替换掉匹配到的子字符串。 |
| String.prototype.split | 一个使用正则表达式或者一个固定字符串分隔一个字符串,并将分隔后的子字符串存储到数组中的 String 方法。 |
练习
匹配任意10位数:
var regex = /^\d{10}$/;
console.log(regex.test('9995484545'));
// true分析下上面的正则:
我们匹配想要跨越整个字符串,不能字符串中有我们要匹配的内容就可以,因此使用^和$限制了开头和结尾;
\d用来匹配数字,它相当于[0-9];
{10}匹配了\d表达式,即\d重复10次;
匹配日期格式DD-MM-YYYY或DD-MM-YY:
var regex = /^(\d{1,2}-){2}\d{2}(\d{2})?$/;
console.log(regex.test('10-01-1990'));
// true
console.log(regex.test('2-01-90'));
// true
console.log(regex.test('10-01-190'));分析上面的正则:
同理我们使用^和$限制了开头和结尾;
\d{1,2},表示匹配1位或2位数字;
-来匹配连字符,无特殊含义;
()包裹了一个子表达式,也叫捕获组;
{2}表示匹配上面的子表达式两次;
\d{2}匹配两位数字;
(\d{2})?子表达式中匹配两位数字,然后匹配子表达式一次或是不匹配;
驼峰命名转下划线命名:
var reg = /(\B[A-Z])/g;
'oneTwoThree'.replace(reg, '_$1').toLowerCase();分析上面的正则:
\B避免将首字母大写的字符也转换掉;
([A-Z])捕获组捕获大写字母;
然后replace里使用$n这样的语法来表示前面的捕获;
调用toLowerCase转为小写字母;
结论
正则表达式各种规则很难记,希望本篇文章可以帮大家更好的去记忆这些特殊字符,也希望大家能写出牛叉的正则表达式。共勉。
最后提供一个练习正则表达式的链接:https://www.hackerrank.com/domains/regex和一个工具网站:https://regex101.com/
参考文章:A Practical Guide to Regular Expressions (RegEx) In JavaScript,正则表达式
公众号:「前端进阶学习」,回复「666」,获取一揽子前端技术书籍
本文内容仅供个人学习、研究或参考使用,不构成任何形式的决策建议、专业指导或法律依据。未经授权,禁止任何单位或个人以商业售卖、虚假宣传、侵权传播等非学习研究目的使用本文内容。如需分享或转载,请保留原文来源信息,不得篡改、删减内容或侵犯相关权益。感谢您的理解与支持!



