为什么我认为数据结构与算法对前端开发很重要?
从一个需求谈起
在我之前的项目中,曾经遇到过这样一个需求,编写一个级联选择器,大概是这样:
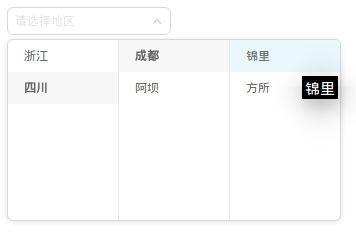
图中的示例使用的是Ant-Design的Cascader组件。
要实现这一功能,我需要类似这样的数据结构:
"value": "浙江",
"children": [{
"value": "杭州",
"children": [{
"value": "西湖"
}]
}]
}, {
"value": "四川",
"children": [{
"value": "成都",
"children": [{
"value": "锦里"
}, {
"value": "方所"
}]
}, {
"value": "阿坝",
"children": [{
"value": "九寨沟"
}]
}]
}]一个具有层级结构的数据,实现这个功能非常容易,因为这个结构和组件的结构是一致的,递归遍历就可以了。
但是,由于后端通常采用的是关系型数据库,所以返回的数据通常会是这个样子:
"province": "浙江",
"city": "杭州",
"name": "西湖"
}, {
"province": "四川",
"city": "成都",
"name": "锦里"
}, {
"province": "四川",
"city": "成都",
"name": "方所"
}, {
"province": "四川",
"city": "阿坝",
"name": "九寨沟"
}]前端这边想要将数据转换一下其实也不难,因为要合并重复项,可以参考数据去重的方法来做,于是我写了这样一个版本。
'use strict'
/**
* 将一个没有层级的扁平对象,转换为树形结构({value, children})结构的对象
* @param {array} tableData - 一个由对象构成的数组,里面的对象都是扁平的
* @param {array} route - 一个由字符串构成的数组,字符串为前一数组中对象的key,最终
* 输出的对象层级顺序为keys中字符串key的顺序
* @return {array} 保存具有树形结构的对象
*/
var transObject = function(tableData, keys) {
let hashTable = {}, res = []
for( let i = 0; i < tableData.length; i++ ) {
if(!hashTable[tableData[i][keys[0]]]) {
let len = res.push({
0]],
children: []
})
// 在这里要保存key对应的数组序号,不然还要涉及到查找
hashTable[tableData[i][keys[0]]] = { $$pos: len - 1 }
}
if(!hashTable[tableData[i][keys[0]]][tableData[i][keys[1]]]) {
let len = res[hashTable[tableData[i][keys[0]]].$$pos].children.push({
1]],
children: []
})
hashTable[tableData[i][keys[0]]][tableData[i][keys[1]]] = { $$pos: len - 1 }
}
res[hashTable[tableData[i][keys[0]]].$$pos].children[hashTable[tableData[i][keys[0]]][tableData[i][keys[1]]].$$pos].children.push({
2]]
})
}
return res
}
"province": "浙江",
"city": "杭州",
"name": "西湖"
}, {
"province": "四川",
"city": "成都",
"name": "锦里"
}, {
"province": "四川",
"city": "成都",
"name": "方所"
}, {
"province": "四川",
"city": "阿坝",
"name": "九寨沟"
}]
var keys = ['province', 'city', 'name']
console.log(transObject(data, keys))还好keys的长度只有3,这种东西长了根本没办法写,很明显可以看出来这里面有重复的部分,可以通过循环搞定,但是想了很久都没有思路,就搁置了。
后来,有一天晚饭后不是很忙,就跟旁边做数据的同事聊了一下这个需求,请教一下该怎么用循环来处理。他看了一下,就问我:“你知道trie树吗?”。我头一次听到这个概念,他简单的给我讲了一下,然后说感觉处理的问题有些类似,让我可以研究一下trie树的原理并试着优化一下。
讲道理,trie树这个数据结构网上确实有很多资料,但很少有使用JavaScript实现的,不过原理倒是不难。尝试之后,我就将transObject的代码优化成了这样。(关于trie树,还请读者自己阅读相关材料)
var transObject = function(tableData, keys) {
let hashTable = {}, res = []
for (let i = 0; i < tableData.length; i++) {
let arr = res, cur = hashTable
for (let j = 0; j < keys.length; j++) {
let key = keys[j], filed = tableData[i][key]
if (!cur[filed]) {
let pusher = {
value: filed
}, tmp
if (j !== (keys.length - 1)) {
tmp = []
pusher.children = tmp
}
cur[filed] = { $$pos: arr.push(pusher) - 1 }
cur = cur[filed]
arr = tmp
} else {
cur = cur[filed]
arr = arr[cur.$$pos].children
}
}
}
return res
}这样,解决方案就和keys的长短无关了。
这大概是我第一次,真正将数据结构的知识和前端项目需求结合在一起。
再谈谈我在面试遇到的问题
目前为止我参加过几次前端开发方面的面试,确实有不少面试官会问道一些算法。通常会涉及的,是链表、树、字符串、数组相关的知识。前端面试对算法要求不高,似乎已经是业内的一种共识了。虽说算法好的前端面试肯定会加分,但是仅凭常见的面试题,而不去联系需求,很难让人觉得,算法对于前端真的很重要。
直到有一天,有一位面试官问我这样一个问题,下面我按照自己的回忆把对话模拟出来,A指面试官,B指我:
A:你有写过瀑布流吗?
B:我写过等宽瀑布流。实现是当用户拉到底部的一定高度的时候,向后端请求一定数量的图片,然后再插入到页面中。
A:那我问一下,如何让几列图片之间的高度差最小?
B:这个需要后端发来的数据里面有图片的高度,然后我就可以看当前高度最小的是哪里列,将新图片插入那一列,然后再看看新的高度最小的是哪一列。
A:我觉得你没有理解我的问题,我的意思是如何给后端发来的图片排序,让几列图片之间的高度差最小?
B:(想了一段时间)对不起,这个问题我没有思路。
A:你是软件工程专业的对吧?你们数据结构课有没有学动态规划?
B:可能有讲吧,但是我没什么印象了。
对话大概就是这样,虽然面试最终还是pass了,但这个问题确实让我很在意,因为我觉得,高度差“最”小,真的能用很简单的算法就解决吗?
这个问题的实质,其实就是有一个数组,将数组元素分成n份,每份所有元素求和,如何使每份的和的差最小。
搜索上面这个问题,很快就能找到相关的解答,很基本的一类动态规划问题——背包问题。
之前我确实看过背包问题的相关概念(也仅仅是相关概念)。当时我看到这样一段话:
许多使用递归去解决的编程问题,可以重写为使用动态规划的技巧去解决。动态规划方案通常会使用一个数组来建立一张表,用于存放被分解成众多子问题的解。当算法执行完毕,最终的解将会在这个表中很明显的地方被找到。
后面是一个用动态规划重写斐波那契数列的例子。我看到它只是将递归的结果,保存在了一个数组中,就天真的以为动态规划是优化递归的一种方法,并没有深入去理解。
不求甚解,确实早晚会出问题的。当时我虽然以为自己知道了算法的重要性,但其实还是太年轻。
动态规划可以求解一类“最优解”问题,这在某种程度上让我耳目一新。由于本文主要还是为了说明数据结构与算法对于前端的意义,关于动态规划的细节,本文也不会涉及,而且水平确实也不够。网上有许多非常好的博文,尤其推荐《背包九讲》。
多说两句——一道思考题
将如下扁平对象,转为树形对象。parent字段为空字符串的节点为根节点:
var input = {
h3: {
parent: 'h2',
name: '副总经理(市场)'
},
h1: {
parent: 'h0',
name: '公司机构'
},
h7: {
parent: 'h6',
name: '副总经理(总务)'
},
h4: {
parent: 'h3',
name: '销售经理'
},
h2: {
parent: 'h1',
name: '总经理'
},
h8: {
parent: 'h0',
name: '财务总监'
},
h6: {
parent: 'h4',
name: '仓管总监'
},
h5: {
parent: 'h4',
name: '销售代表'
},
h0: {
parent: '',
name: 'root'
}
};这个需求在前端其实也很实际,示例中的对象是一个公司组织结构图。如果需求是让你在前端用svg之类的技术画出这样一张图,就需要这个功能。(另外我想到的一种应用场景,就是在前端展示类似windows资源管理器的文件树)
我当时想了很久,没有想到一个循环解决的方法,后来在stackoverflow上找到了答案:
var plain2Tree = function (obj) {
var key, res
for(key in obj) {
var parent = obj[key].parent
if(parent === '') {
res = obj[key]
} else {
obj[parent][key] = obj[key]
}
}
return res
}这段代码,就是利用了JavaScript里面的引用类型,之后的思路,和操作指针没什么区别,就是构造一棵树。
但对于我来说,从来都没有往树和指针的那方面思考,就很被动了。
结语
以上列举了三道题,希望可以引起大家对于在前端应用数据结构与算法相关知识的共鸣。
来自:LeuisKen
本文内容仅供个人学习、研究或参考使用,不构成任何形式的决策建议、专业指导或法律依据。未经授权,禁止任何单位或个人以商业售卖、虚假宣传、侵权传播等非学习研究目的使用本文内容。如需分享或转载,请保留原文来源信息,不得篡改、删减内容或侵犯相关权益。感谢您的理解与支持!

