JS数据结构与算法_树
一、递归
学习树离不开递归。
1.1 介绍
递归是一种解决问题的方法,它解决问题的各个小部分,直到解决最初的大问题。递归通常涉及函数调用自身。
通俗的解释:年级主任需要知道某个年级的数学成绩的平均值,他没法直接得到结果;年级主任需要问每个班的数学老师,数学老师需要问班上每个同学;然后再沿着学生-->老师-->主任这条线反馈,才能得到结果。递归也是如此,自己无法直接解决问题,将问题给下一级,下一级若无法解决,再给下一级,直到有结果再依次向上反馈。
我们常见的使用递归解决的问题,如下:
// 斐波拉契数列
function fibo(n) {
if (n === 0 || n === 1) return n; // 边界
return fibo(n - 1) + fibo(n - 2);
}
// 阶乘
function factorial(n) {
if (n === 0 || n === 1) return 1; // 边界
return facci(n - 1) * n;
}他们有共同的特点,也是递归的特点:
- 有边界条件,防止无限递归
- 函数自身调用
1.2 高效递归的两个方法
以斐波拉契数列举例,下面是n=6时斐波拉契数列的计算过程。
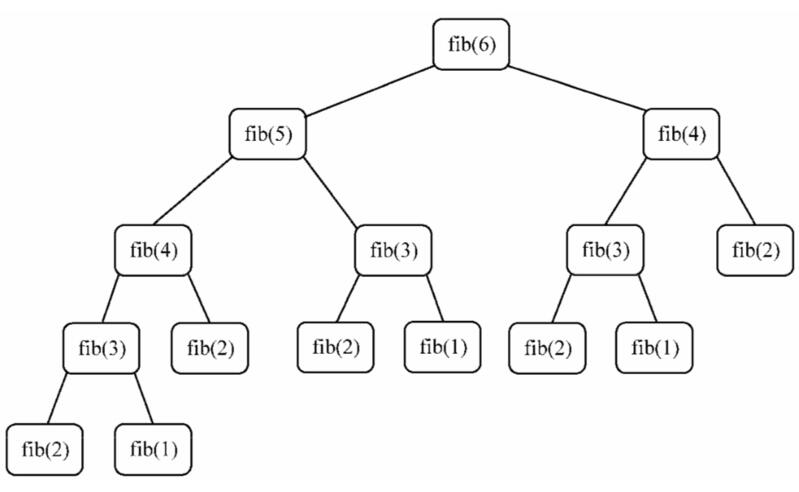
我们可以发现,这里面存在许多重复的计算,数列越大重复计算越多。
如何避免呢?利用缓存,将fib(n)计算后的值存储,后面使用时,若存在直接取用,不存在则计算
(1)缓存Memoizer
const fibo_memo = function() {
const temp = {0: 0, 1: 1}; // 需要用闭包缓存
return function fib(n) {
if (!(n in temp)) { // 缓存中无对应数据时,向下计算查找
temp[n] = fib(n - 1) + fib(n - 2);
}
return temp[n];
}
}()(2)递推法(动态规划)
动态规划并不属于高效递归,但是也是有效解决问题的一个方法。
动态规划:从底部开始解决问题,将所有小问题解决掉,然后合并成一个整体解决方案,从而解决掉整个大问题;
递归:从顶部开始将问题分解,通过解决掉所有分解的小问题来解决整个问题;
使用动态规划解决斐波那契数列
function fibo_dp(n) {
let current = 0;
let next = 1;
for(let i = 0; i < n; i++) {
[current, next] = [next, current + next];
}
return current;
}(3)效率对比
const arr = Array.from({length: 40}, (_, i) => i);
// 普通
console.time('fibo');
arr.forEach((e) => { fibo(e); });
console.timeEnd('fibo');
// 缓存
console.time('fibo_memo');
arr.forEach((e) => { fibo_memo(e); });
console.timeEnd('fibo_memo');
// 动态规划
console.time('fibo_dp');
arr.forEach((e) => { fibo_dp(e); });
console.timeEnd('fibo_dp');
// 打印结果【40】
fibo: 1869.665ms
fibo_memo: 0.088ms
fibo_dp: 0.326ms
// 当打印到【1000】时,普通的已溢出
fibo_memo: 0.370ms
fibo_dp: 16.458ms总结:从上面的对比结果可知,使用缓存的性能最佳
二、树
一个树结构包含一系列存在父子关系的节点。每个节点都有一个父节点(除了顶部的第一个节点)以及零个或多个子节点:
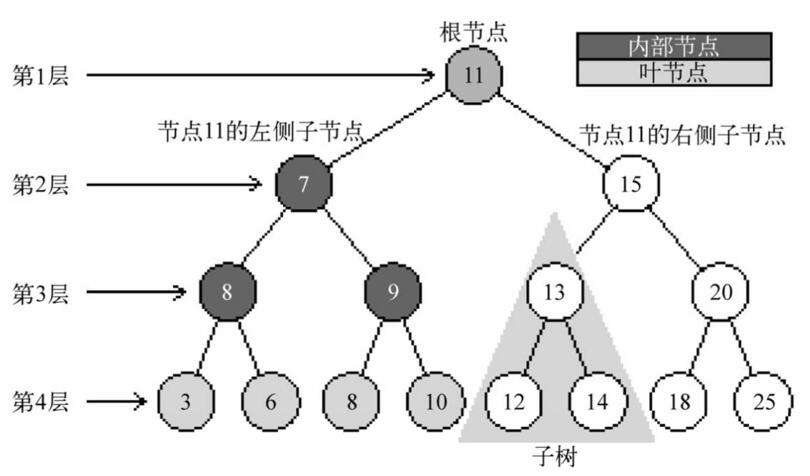
2.1 相关术语
- 节点:树中的每个元素都叫作节点;
- 根节点:位于树顶部的节点叫作根节点;
- 内部节点/分支节点:至少有一个子节点的节点称为内部节点或;
- 外部节点/叶节点:没有子元素的节点称为外部节点或叶节点;
- 子女节点:7和15为11的子女节点
- 父节点:11为7和15的父节点
- 兄弟节点:同一个父节点的子女节点互称为兄弟;7和15互为兄弟节点
- 祖先节点:从根节点到该节点所经过分支上的所有节点;如节点3的祖先节点为 11,7,8
- 子孙节点:以某一节点构成的子树,其下所有节点均为其子孙节点;如12和14为13的子孙节点
- 节点所在层次:根节点为1层,依次向下
- 节点的度:树中距离根节点最远的节点所处的层次就是树的深度;上图中,树的深度是4
- 节点的度:结点拥有子结点的数量;
- 树的度:树中节点的度的最大值;
- 有序树
- 无序树
关于数的深度和高度的问题,不同的教材有不同的说法,具体可以参考树的高度和深度以及结点的高度和深度这篇文章
2.2 认识二叉搜索树BST
2.2.1 定义
二叉树是树的一种特殊情况,每个节点最多有有两个子女,分别称为该节点的左子女和右子女,就是说,在二叉树中,不存在度大于2的节点。
二叉搜索树(BST)是二叉树的一种,但是它只允许你在左侧节点存储(比父节点)小的值, 在右侧节点存储(比父节点)大(或者等于)的值。
上图展示的便是二叉搜索数
2.2.2 特点
- 同一层,数值从左到右依次增加
- 以某一祖先节点为参考,该节点左侧值均小于节点值,右侧值均大于节点值
- 在二叉树的第i(i>=1)层,最多有x^(i-1)个节点
- 深度为k(k>=0)的二叉树,最少有k个节点,最多有2^(k-1)个节点
- 对于一棵非空二叉树,叶节点的数量等于度为2的节点数量加1
满二叉树:深度为k的满二叉树,是有2^(k-1)个节点的二叉树,每一层都达到了可以容纳的最大数量的节点
2.2.3 基础方法
- insert(key): 向树中插入一个新的键;
- inOrderTraverse: 通过中序遍历方式遍历所有节点
- preOrderTraverse: 通过先序遍历方式遍历所有节点
- postOrderTraverse: 通过后序遍历方式遍历所有节点
- getMin: 返回树中最小的值/键
- getMax: 返回树中最大的值/键
- find(key): 在树中查找一个键,如果节点存在则返回该节点不存在则返回null;
- remove(key): 从树中移除某个键
2.3 BST的实现
2.3.1 基类
// 基类
class BinaryTreeNode {
constructor(data) {
this.key = data;
this.left = null;
this.right = null;
}
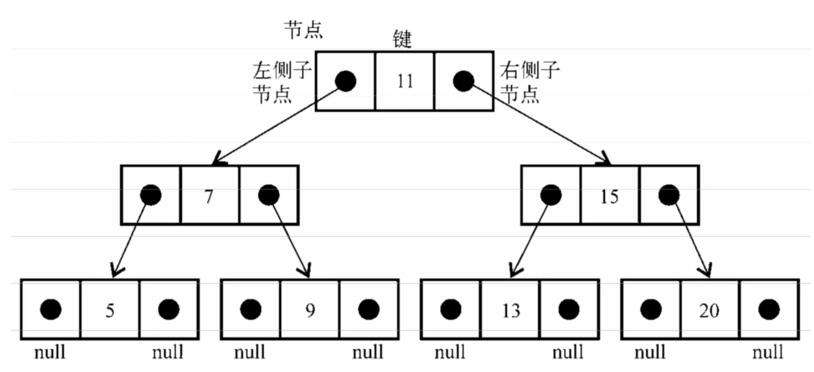
}下图展现了二叉搜索树数据结构的组织方式:
2.3.2 BST类
//二叉查找树(BST)的类
class BinarySearchTree {
constructor() {
this.root = null; // 根节点
}
insert(){} // 插入节点
preOrderTraverse(){} // 先序遍历
inOrderTraverse(){} // 中序遍历
postOrderTraverse(){} // 后序遍历
search(){} // 查找节点
getMin(){} // 查找最小值
getMax(){} // 查找最大值
remove(){} // 删除节点
}2.3.3 insert方法
insert某个值到树中,必须依照二叉搜索树的规则【每个节点Key值唯一,最多有两个节点,且左侧节点值<父节点值<右侧节点值】
不同情况具体操作如下:
- 根节点为null,直接赋值插入节点给根节点;
- 根节点不为null,按照BST规则找到left/right为null的位置并赋值
insert(key) {
const newNode = new BinaryTreeNode(key);
if (this.root !== null) {
this.insertNode(this.root, newNode);
} else {
this.root = newNode;
}
}
insertNode(node, newNode) {
if (newNode.key < node.key) {
if (node.left === null) {// 左侧
node.left = newNode;
} else {
this.insertNode(node.left, newNode);
}
} else {
if (node.right === null) {// 右侧
node.right = newNode;
} else {
this.insertNode(node.right, newNode);
}
}
}下图为在已有BST的基础上插入值为6的节点,步骤如下:
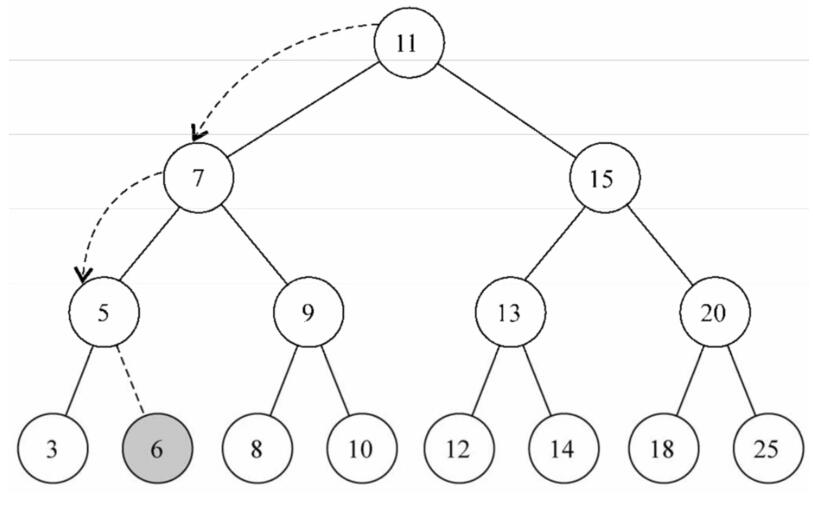
- 有无根节点?有;对比根节点值(6<11),根节点左侧判断;
- 第二层左侧节点是否为null?不为;对比第二层左侧节点的值(6<7),继续左侧判断;
- 第三层左侧节点是否为null?不为;对比第三层左侧节点的值(6>5),以右侧判断;
- 第四层右侧节点是否为null?为;插入该处
2.3.4 树的遍历
树的遍历,核心为递归:根节点需要找到其每一个子孙节点,但是并不知道这棵树有多少层。因此,它找到其子节点,子节点也不知道,依次向下找,直到叶节点。
访问树的所有节点有三种方式:中序、先序和后序。下面依次介绍
(1)中序遍历
中序遍历是一种以上行顺序访问BST所有节点的遍历方式,也就是以从最小到最大的顺序访问所有节点。中序遍历的一种应用就是<u>对树进行排序操作</u>
inOrderTraverse(callback) {
this.inOrderTraverseNode(this.root, callback);
}
inOrderTraverseNode(node, callback) {
if (node !== null) {
this.inOrderTraverseNode(node.left, callback);
callback(node.key);
this.inOrderTraverseNode(node.right, callback);
}
}下面的图描绘了中序遍历方法的访问路径:
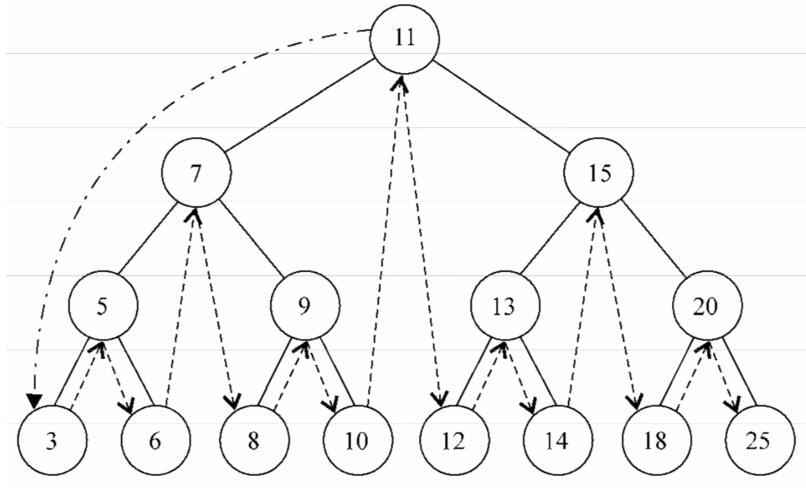
(2)先序遍历
先序遍历是以优先于后代节点的顺序访问每个节点的。先序遍历的一种应用是<u>打印一个结构化的文档</u>
preOrderTraverse(callback) {
this.preOrderTraverseNode(this.root, callback);
}
preOrderTraverseNode(node, callback) {
if (node !== null) {
callback(node.key);
this.preOrderTraverseNode(node.left, callback);
this.preOrderTraverseNode(node.right, callback);
}
}下面的图描绘了先序遍历方法的访问路径:
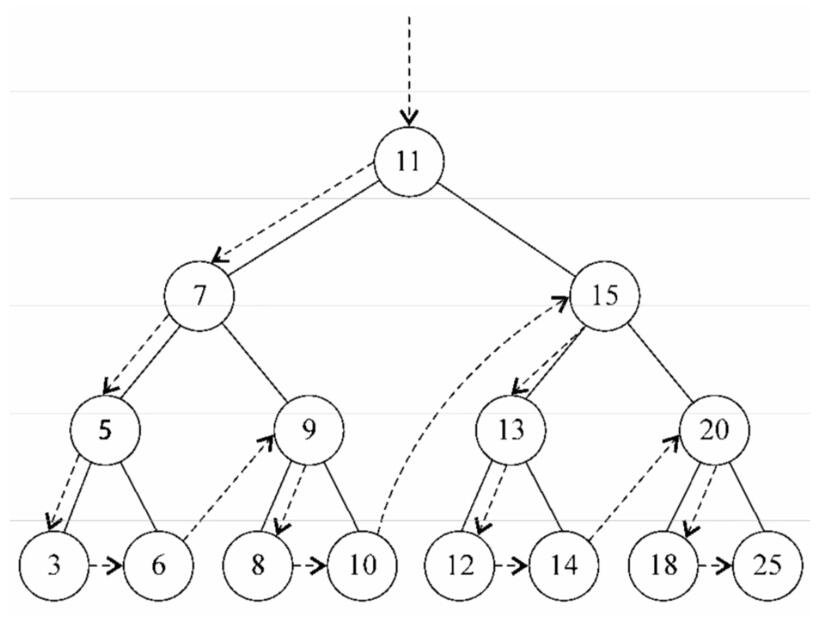
(3)后序遍历
后序遍历则是先访问节点的后代节点,再访问节点本身。后序遍历的一种应用是<u>计算一个目录和它的子目录中所有文件所占空间的大小</u>
postOrderTraverse(callback) {
this.postOrderTraverseNode(this.root, callback);
}
postOrderTraverseNode(node, callback) {
if (node !== null) {
this.postOrderTraverseNode(node.left, callback);
this.postOrderTraverseNode(node.right, callback);
callback(node.key);
}
}下面的图描绘了后序遍历方法的访问路径:
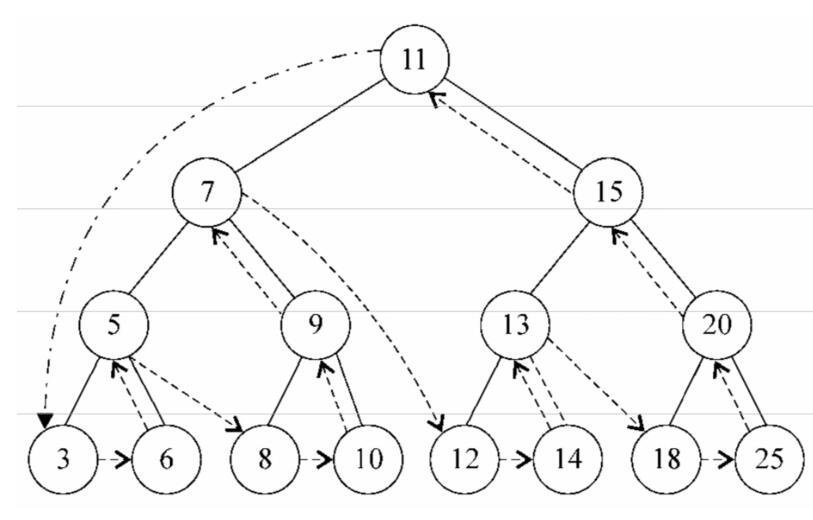
2.3.5 查找方法
(1)最值
观察下图,我们可以非常直观的发现左下角为最小值,右下角为最大值
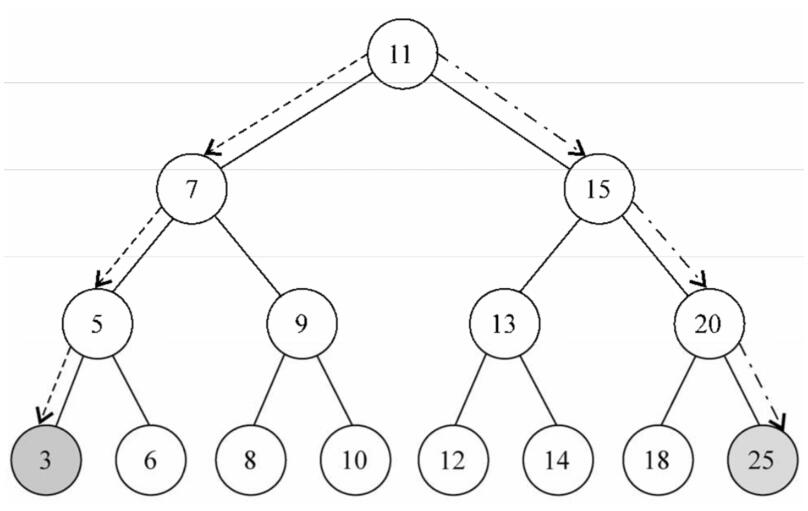
具体代码实现如下
getMin() {
const ret = this.getMinNode();
return ret && ret.key;
}
getMinNode(node = this.root) {
if (node) {
while (node && node.left !== null) {
node = node.left;
}
}
return node;
}
getMax() {
const ret = this.getMaxNode();
return ret && ret.key;
}
getMaxNode(node = this.root) {
if (node) {
while (node && node.right !== null) {
node = node.right;
}
}
return node;
}(2)find()方法
递归找到与目标key值相同的节点,并返回;具体实现如下:
find(key) {
return this.findNode(this.root, key);
}
findNode(node, key) {
if (node === null) {
return null;
}
if (key < node.key) {
return this.findNode(node.left, key);
}
if (key > node.key) {
return this.findNode(node.right, key);
}
return node;
}2.3.6 remove()方法
移除节点是这一类方法中最为复杂的操作,首先需要找到目标key值对应的节点,然后根据不同的目标节点类型需要有不同的操作
remove(key) {
return this.removeNode(this.root, key);
}
removeNode(node, key) {
if (node === null) {
return null;
}
if (key < node.key) { // 目标key小于当前节点key,继续向左找
node.left = this.removeNode(node.left, key);
return node;
}
if (key > node.key) { // 目标key小于当前节点key,继续向右找
node.right = this.removeNode(node.right, key);
return node;
}
// 找到目标位置
if (node.left === null && node.right === null) { // 目标节点为叶节点
node = null;
return node;
}
if (node.right === null) { // 目标节点仅有左侧节点
node = node.left;
return node;
}
if (node.left === null) { // 目标节点仅有右侧节点
node = node.right;
return node;
}
// 目标节点有两个子节点
const tempNode = this.getMinNode(node.right); // 右侧最小值
node.key = tempNode.key;
node.right = this.removeNode(node.right, node.key);
return node;
}目标节点为叶节点图例:子节点赋值为null,并将目标节点指向null
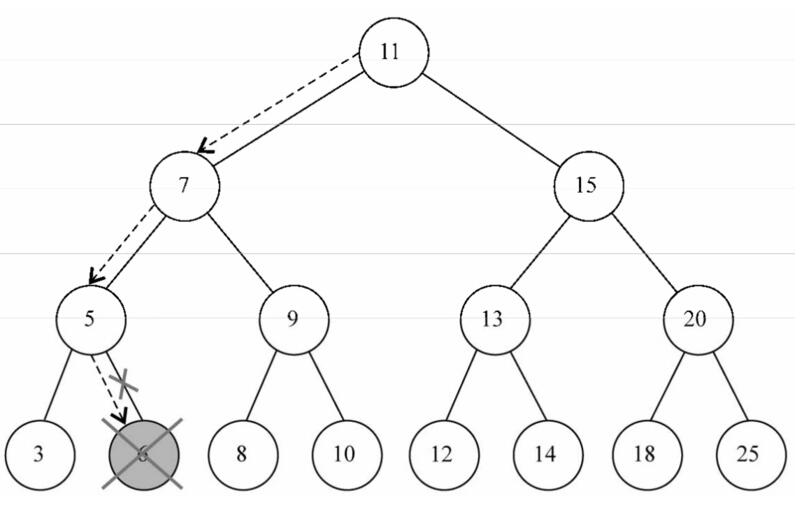
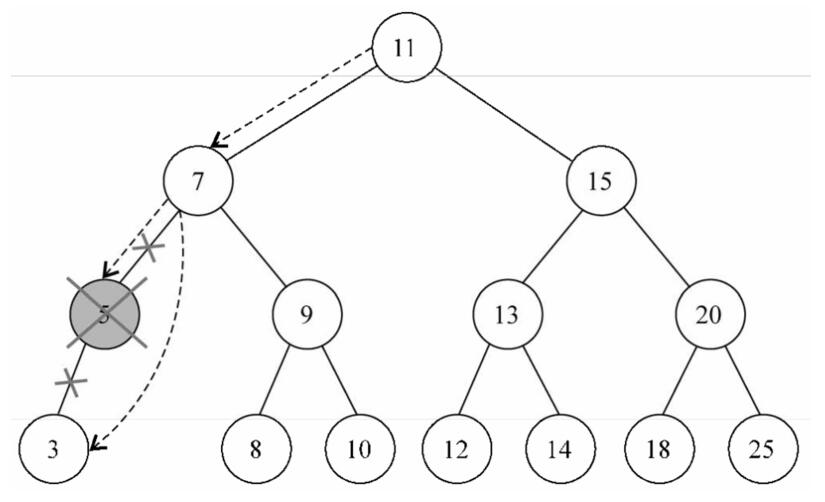
目标节点为仅有左侧子节点或右侧子节点图例:将目标节点的父节点指向子节点
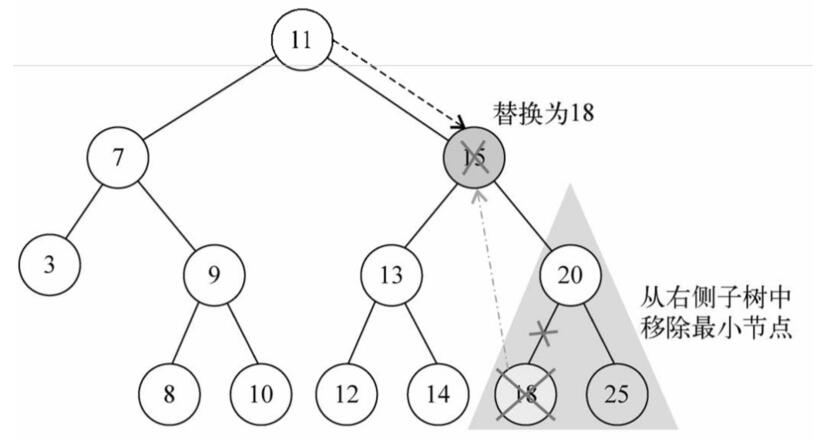
目标节点有两个子节点:根据BST的构成规则,以目标节点右侧树最小值替换重新连接
本文内容仅供个人学习、研究或参考使用,不构成任何形式的决策建议、专业指导或法律依据。未经授权,禁止任何单位或个人以商业售卖、虚假宣传、侵权传播等非学习研究目的使用本文内容。如需分享或转载,请保留原文来源信息,不得篡改、删减内容或侵犯相关权益。感谢您的理解与支持!

