通过实例学习正则表达式
判断邮箱是否正确
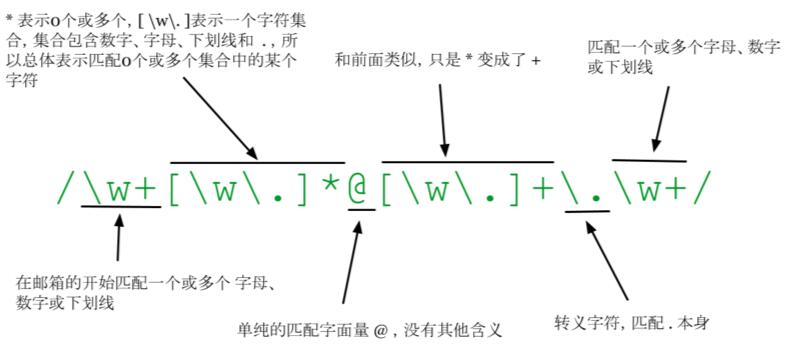
邮箱正则
/\w+[\w\.]*@[\w\.]+\.\w+/测试用例
const regex = /\w+[\w\.]*@[\w\.]+\.\w+/
regex.test('666@email.com') // true
regex.test('july@e.c') // true
regex.test('_@email.com.cn') // true
regex.test('july_1234@email.com') // true
regex.test('@email.com') // false
regex.test('julyemail.com') // false
regex.test('july.email.com') // false
regex.test('july@') // false
regex.test('july@email') // false
regex.test('july@email.') // false
regex.test('july@.') // false
regex.test('july@.com') // false
regex.test('-~!#$%@email.com') // false正则讲解
- \w。 \w属于一种预定义模式,表示匹配任意的字母、数字和下划线。点击查看其他预定义模式。
- +、*。 +、*和?在正则表达式中被称为量词符。+表示一次或多次,*表示0次或多次,?表示0次或一次。
- \. 。 . 在正则表达式中被称为元字符,它可以匹配除回车(\r)、换行(\n) 、行分隔符(\u2028)和段分隔符(\u2029)以外的所有字符。因为元字符有特殊含义,所以如果要匹配元字符本身,就需要使用转义字符,也就是在前面加上反斜杠 ( \ )。点击查看其他元字符
- [\w\.]。 [ ] 表示一个字符集合,比如 [ july ] 不是表示匹配整个单词,而是表示j、u、l和y组成的一个字符集合,匹配时只要匹配到其中一个字母就表示匹配成功。点击查看字符集合详解
- 总览
匹配URL地址
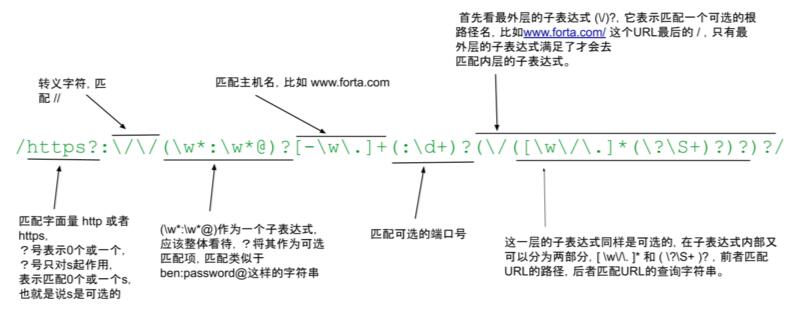
URL正则
/https?:\/\/(\w*:\w*@)?[-\w\.]+(:\d+)?(\/([\w\/\.]*(\?\S+)?)?)?/测试用例
const regex = /https?:\/\/(\w*:\w*@)?[-\w\.]+(:\d+)?(\/([\w\/\.]*(\?\S+)?)?)?/
regex.test('http://www.forta.com/blog') // true
regex.test('https://www.forta.com:80/blog/index.cfm') // true
regex.test('https://www.forta.com') // true
regex.test('http://ben:password@www.forta.com/') // true
regex.test('http://localhost/index.php?ab=1&c=2') // true
regex.test('http://localhost:8500/') // true正则讲解
- ( ) 。类似于( \w:\w*@ )这样的表达式被称为子表达式,相比于字符集合[ ]匹配时只匹配集合中的一个字符,子表达式是将括号内的表达式作为一个整体来匹配。比如 ( :\d+ )匹配类似于 “:8080” 这样的字符串,而 [ :\d ] 匹配一个 : 或者一个 数字。
- 总览
练习
去掉html文件中的所有注释
html文件
我在本地随便写了一个html文件,包含css、html和js3个部分,是一个完整的网页。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Document</title>
<style>
/*
这是css的多行注释
这是css的多行注释 这是css的多行注释
*/
* {
margin: 0;
padding: 0;
/* 这是css的多行注释 */
}
html {
color: #000;
}
</style>
</head>
<body>
<h1>h1 title</h1> <!-- 这是html注释 -->
<h2>h2 title</h2>
<!-- 这是html注释 -->
<button style="/* 这是行内css的注释 */color: red/* 这是行内css的注释 */">click me</button>
<button onclick="/* 这是行内js的注释 */alert('july')/* 这是行内js的注释 */">click me 2</button>
<!--
这是html注释
-->
<button onclick="// 这是行内js的注释
alert(/* 注释 */'july')
//这是行内js的注释 'sdfs' " style='color: blue'>click me 3</button>
<!-- 这是html注释 -->
<script>
// 这是js单行注释
// 这是js单行注释 这是js单行注释
function func() {
console.log('test'); // 这是js单行注释
}
/*
* 这是js多行注释
* 这是js多行注释 这是js多行注释
*/
function func2() {
// 这是js单行注释
/*
这是js多行注释
*/
console.log('test'); /*
这是js多行注释 */
}
</script>
</body>
</html>匹配
const htmlStr = `html字符串`; // 将上面的html内容拷贝于此,由于太长,就不再拷贝
// 匹配 /* */
htmlStr.match(/\/\*[^]*?\*\//g); // 该行代码会返回一个数组,长度为10,数组的每个元素分别对应匹配到的 /* */,由于篇幅有限,就不将结果展示到这里了
// 匹配 <!-- -->
htmlStr.match(/<!--[^]*?-->/g);
// 匹配 //
htmlStr.match(/(\/\/.*?(?=(["']\s*\w+\s*=)|(["']\s*>)))|(\/\/.*)/g);
分析
- g全局修饰符。g是正则表达式的修饰符,表示全局匹配或者搜索,因为html中会有多个注释,所以需要全局修饰符(点击查看全部修饰符)。
- [^]。^被称为脱字符,我的理解就是取反的意思,比如[ ^abc ]表示除了a、b和c,其他所有字符都可以匹配。[^]匹配任意字符,包括换行符。
- 非贪婪模式。量词符在默认情况下都是使用贪婪模式进行匹配,比如说上面的[^]*表示匹配0个或多个任意字符,由于是贪婪模式,所以会尽可能多的匹配任意字符,直到不满足条件为止。通过在[^]*后面加一个?号,就变成了非贪婪模式,这种模式下,一旦条件满足,就不会再往下匹配。想要实际查看两种模式的区别,可以将上方匹配 /* */的正则表达式的?去掉再执行,看看返回结果有何不同。
- 向前查找。向前查找就是一个以?=开头的子表达式。举例说明其意义,比如我们要匹配出URL的协议部分,URL:https://www.forta.com,正则:/.+(?=:)/,(?=:)就是一个向前查找,它表示只要匹配到:,就把:之前的内容返回,:本身不需要返回。
- 前面两种注释的匹配比较容易,第三种也就是//这种注释比较复杂。其实对于//注释,在绝大多数情况下/\/\/.*/这个正则可以匹配出,但是有两种情况不能满足,见下方代码
<button onclick="
alert('july')
//这是行内js的注释 'sdfs' " style='color: blue'>click me 3</button>
<button onclick="
alert('july')
//这是行内js的注释 'sdfs' ">click me 3</button>我们通过图片详细解析一下
最终代码
为了方便,最终代码选择在node环境中执行,因为最初的需求是将html中的所有注释去掉,所以我们使用了字符串的replace方法,该方法接收两个参数,第一个参数是正则表达式,第二个参数是需要替换成的内容。
const fs = require('fs');
// regex.html 是放在同级目录下的html源文件
fs.readFile('./regex.html', 'utf8', (err, data) => {
if (err) throw err;
console.log(
data
.replace(/\/\*[^]*?\*\//g, '') // 替换 /* */
.replace(/<!--[^]*?-->/g, '') // 替换 <!-- -->
.replace(/(\/\/.*?(?=(["']\s*\w+\s*=)|(["']\s*>)))|(\/\/.*)/g, '') // 替换 //
);
});来自:https://segmentfault.com/a/1190000020171825
本文内容仅供个人学习、研究或参考使用,不构成任何形式的决策建议、专业指导或法律依据。未经授权,禁止任何单位或个人以商业售卖、虚假宣传、侵权传播等非学习研究目的使用本文内容。如需分享或转载,请保留原文来源信息,不得篡改、删减内容或侵犯相关权益。感谢您的理解与支持!



