ES6 尾调用和尾递归
最近在重温ES6,学习到尾调用,所以做了一些摘记和小结。
什么是尾调用?
尾调用(Tail Call)是函数式编程的一个重要概念,本身非常简单,一句话就能说清楚,就是指某个函数的最后一步是调用另一个函数。
function f(x){
return g(x);
}上面代码中,函数f的最后一步是调用函数g,这就叫尾调用。
以下三种情况,都不属于尾调用。
// 情况一
function f(x){
let y = g(x);
return y;
}
// 情况二
function f(x){
return g(x) + 1;
}
// 情况三
function f(x){
g(x);
}上面代码中,情况一是调用函数g之后,还有赋值操作,所以不属于尾调用,即使语义完全一样。情况二也属于调用后还有操作,即使写在一行内。情况三等同于下面的代码。
function f(x){
g(x);
return undefined;
}尾调用不一定出现在函数尾部,只要是最后一步操作即可。
function f(x) {
if (x > 0) {
return m(x)
}
return n(x);
}上面代码中,函数m和n都属于尾调用,因为它们都是函数f的最后一步操作。
严格模式
ES6 的尾调用优化只在严格模式下开启,正常模式是无效的。
这是因为在正常模式下,函数内部有两个变量,可以跟踪函数的调用栈。
* func.arguments:返回调用时函数的参数。
* func.caller:返回调用当前函数的那个函数。尾调用优化发生时,函数的调用栈会改写,因此上面两个变量就会失真。严格模式禁用这两个变量,所以尾调用模式仅在严格模式下生效。
function restricted() {
'use strict';
restricted.caller; // 报错
restricted.arguments; // 报错
}
restricted();尾调用优化
尾调用之所以与其他调用不同,就在于它的特殊的调用位置。
我们知道,函数调用会在内存形成一个“调用记录”,又称“调用帧”(call frame),保存调用位置和内部变量等信息。如果在函数A的内部调用函数B,那么在A的调用帧上方,还会形成一个B的调用帧。等到B运行结束,将结果返回到A,B的调用帧才会消失。如果函数B内部还调用函数C,那就还有一个C的调用帧,以此类推。所有的调用帧,就形成一个“调用栈”(call stack)。
话不多说,举个例子
function foo () { console.log(111); }
function bar () { foo(); }
function baz () { bar(); }
baz();调用栈情况参考下图:
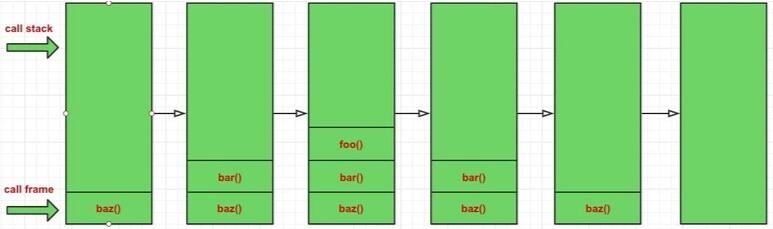
造成这种结果是因为每个函数在调用另一个函数的时候,并没有 return 该调用,所以JS引擎会认为你还没有执行完,会保留你的调用帧。
baz() 里面调用了 bar() 函数,并没有 return 该调用,所以在调用栈中保持自己的调用帧,同时 bar() 函数的调用帧在调用栈中生成,同理,bar() 函数又调用了 foo() 函数,最后执行到 foo() 函数的时候,没有再调用其他函数,这里没有显示声明 return,所以这里默认 return undefined。
foo() 执行完了,销毁调用栈中自己的记录,依次销毁 bar() 和 baz() 的调用帧,最后完成整个流程。
如果对上面的例子做如下修改:
function foo () { console.log(111); }
function bar () { return foo(); }
function baz () { return bar(); }
baz();如果尾调用优化生效,流程图就会变成这样:
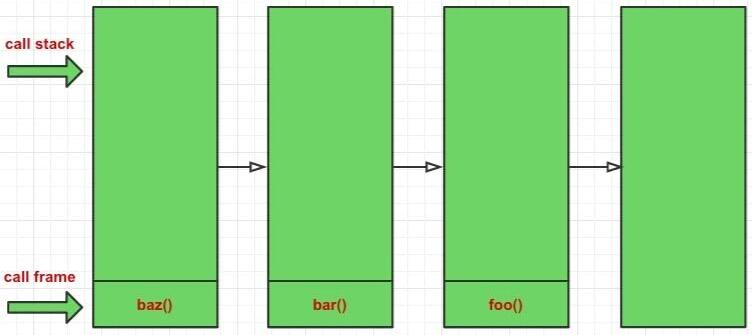
我们可以很清楚的看到,尾调用由于是函数的最后一步操作,所以不需要保留外层函数的调用记录,只要直接用内层函数的调用记录取代外层函数的调用记录就可以了,调用栈中始终只保持了一条调用帧。
这就叫做尾调用优化(Tail call optimization),即只保留内层函数的调用帧。如果所有的函数都是尾调用的话,调用位置、内部变量等信息都不会再用到了,那么在调用栈中的调用帧始终只有一条,这样会节省很大一部分的内存,这也是尾调用优化的意义。
function f() {
let m = 1;
let n = 2;
return g(m + n);
}
f();
// 等同于
function f() {
return g(3);
}
f();
// 等同于
g(3);上面代码中,如果函数g不是尾调用,函数f就需要保存内部变量m和n的值、g的调用位置等信息。但由于调用g之后,函数f就结束了,所以执行到最后一步,完全可以删除f(x)的调用帧,只保留g(3)的调用帧。
注意,只有不再用到外层函数的内部变量,内层函数的调用帧才会取代外层函数的调用帧,否则就无法进行“尾调用优化”。
function addOne(a){
var one = 1;
function inner(b){
return b + one;
}
return inner(a);
}上面的函数不会进行尾调用优化,因为内层函数inner用到了外层函数addOne的内部变量one。
注意,目前只有 Safari 浏览器支持尾调用优化,Chrome 和 Firefox 都不支持。
尾递归优化
函数调用自身,称为递归。如果尾调用自身,就称为尾递归。
递归非常耗费内存,因为需要同时保存成千上百个调用帧,很容易发生“栈溢出”错误(stack overflow)。但对于尾递归来说,由于只存在一个调用帧,所以永远不会发生“栈溢出”错误。
function factorial(n) {
if (n === 1) return 1;
return n * factorial(n - 1);
}
factorial(5) // 120上面代码是一个阶乘函数,计算n的阶乘,最多需要保存n个调用记录,空间复杂度 O(n) 。
如果改写成尾递归,只保留一个调用记录,空间复杂度 O(1) 。
function factorial(n, total) {
if (n === 1) return total;
return factorial(n - 1, n * total);
}
factorial(5, 1) // 120还有一个比较著名的例子,就是计算 Fibonacci 数列,也能充分说明尾递归优化的重要性。
非尾递归的 Fibonacci 数列实现如下。
function Fibonacci (n) {
if ( n <= 1 ) {return 1};
return Fibonacci(n - 1) + Fibonacci(n - 2);
}
Fibonacci(10) // 89
Fibonacci(100) // 超时
Fibonacci(500) // 超时尾递归优化过的 Fibonacci 数列实现如下。
function Fibonacci2 (n , ac1 = 1 , ac2 = 1) {
if( n <= 1 ) {return ac2};
return Fibonacci2 (n - 1, ac2, ac1 + ac2);
}
Fibonacci2(100) // 573147844013817200000
Fibonacci2(1000) // 7.0330367711422765e+208
Fibonacci2(10000) // Infinity由此可见,“尾调用优化”对递归操作意义重大,所以一些函数式编程语言将其写入了语言规格。ES6 亦是如此,第一次明确规定,所有 ECMAScript 的实现,都必须部署“尾调用优化”。这就是说,ES6 中只要使用尾递归,就不会发生栈溢出(或者层层递归造成的超时),相对节省内存。
递归函数的改写
尾递归的实现,往往需要改写递归函数,确保最后一步只调用自身。做到这一点的方法,就是把所有用到的内部变量改写成函数的参数。比如上面的例子,阶乘函数 factorial 需要用到一个中间变量total,那就把这个中间变量改写成函数的参数。这样做的缺点就是不太直观,第一眼很难看出来,为什么计算5的阶乘,需要传入两个参数5和1?
两个方法可以解决这个问题。方法一是在尾递归函数之外,再提供一个正常形式的函数。
function tailFactorial(n, total) {
if (n === 1) return total;
return tailFactorial(n - 1, n * total);
}
function factorial(n) {
return tailFactorial(n, 1);
}
factorial(5) // 120上面代码通过一个正常形式的阶乘函数factorial,调用尾递归函数tailFactorial,看起来就正常多了。
函数式编程有一个概念,叫做柯里化(currying),意思是将多参数的函数转换成单参数的形式。这里也可以使用柯里化。
function currying(fn, n) {
return function (m) {
return fn.call(this, m, n);
};
}
function tailFactorial(n, total) {
if (n === 1) return total;
return tailFactorial(n - 1, n * total);
}
const factorial = currying(tailFactorial, 1);
factorial(5) // 120上面代码通过柯里化,将尾递归函数tailFactorial变为只接受一个参数的factorial。
第二种方法就简单多了,就是采用 ES6 的函数默认值。
function factorial(n, total = 1) {
if (n === 1) return total;
return factorial(n - 1, n * total);
}
factorial(5) // 120上面代码中,参数total有默认值1,所以调用时不用提供这个值。
总结一下,递归本质上是一种循环操作。纯粹的函数式编程语言没有循环操作命令,所有的循环都用递归实现,这就是为什么尾递归对这些语言极其重要。对于其他支持“尾调用优化”的语言(比如 Lua,ES6),只需要知道循环可以用递归代替,而一旦使用递归,就最好使用尾递归。
尾递归优化的实现
尾递归优化只在严格模式下生效,那么正常模式下,或者那些不支持该功能的环境中,有没有办法也使用尾递归优化呢?回答是可以的,就是自己实现尾递归优化。
它的原理非常简单。尾递归之所以需要优化,原因是调用栈太多,造成溢出,那么只要减少调用栈,就不会溢出。怎么做可以减少调用栈呢?就是采用“循环”换掉“递归”。
下面是一个正常的递归函数。
function sum(x, y) {
if (y > 0) {
return sum(x + 1, y - 1);
} else {
return x;
}
}
sum(1, 100000)
// Uncaught RangeError: Maximum call stack size exceeded(…)上面代码中,sum是一个递归函数,参数x是需要累加的值,参数y控制递归次数。一旦指定sum递归 100000 次,就会报错,提示超出调用栈的最大次数。
蹦床函数(trampoline)可以将递归执行转为循环执行。
function trampoline(f) {
while (f && f instanceof Function) {
f = f();
}
return f;
}上面就是蹦床函数的一个实现,它接受一个函数f作为参数。只要f执行后返回一个函数,就继续执行。注意,这里是返回一个函数,然后执行该函数,而不是函数里面调用函数,这样就避免了递归执行,从而就消除了调用栈过大的问题。
然后,要做的就是将原来的递归函数,改写为每一步返回另一个函数。
function sum(x, y) {
if (y > 0) {
return sum.bind(null, x + 1, y - 1);
} else {
return x;
}
}上面代码中,sum函数的每次执行,都会返回自身的另一个版本。
现在,使用蹦床函数执行sum,就不会发生调用栈溢出。
trampoline(sum(1, 100000))
// 100001蹦床函数并不是真正的尾递归优化,下面的实现才是。
function tco(f) {
var value;
var active = false;
var accumulated = [];
return function accumulator() {
accumulated.push(arguments);
if (!active) {
active = true;
while (accumulated.length) {
value = f.apply(this, accumulated.shift());
}
active = false;
return value;
}
};
}
var sum = tco(function(x, y) {
if (y > 0) {
return sum(x + 1, y - 1)
}
else {
return x
}
});
sum(1, 100000)
// 100001上面代码中,tco函数是尾递归优化的实现,它的奥妙就在于状态变量active。默认情况下,这个变量是不激活的。一旦进入尾递归优化的过程,这个变量就激活了。然后,每一轮递归sum返回的都是undefined,所以就避免了递归执行;而accumulated数组存放每一轮sum执行的参数,总是有值的,这就保证了accumulator函数内部的while循环总是会执行。
这样就很巧妙地将“递归”改成了“循环”,而后一轮的参数会取代前一轮的参数,保证了调用栈只有一层。
来源:https://segmentfault.com/a/1190000020694801
本文内容仅供个人学习、研究或参考使用,不构成任何形式的决策建议、专业指导或法律依据。未经授权,禁止任何单位或个人以商业售卖、虚假宣传、侵权传播等非学习研究目的使用本文内容。如需分享或转载,请保留原文来源信息,不得篡改、删减内容或侵犯相关权益。感谢您的理解与支持!