JavaScript 的共享传递和按值传递
关于JavaScript如何将值传递给函数,在互联网上有很多误解和争论。大致认为,参数为原始数据类时使用按值传递,参数为数组、对象和函数等数据类型使用引用传递。
按值传递 和 引用传递参数 主要区别简单可以说:
- 按值传递:在函数里面改变传递的值不会影响到外面
- 引用传递:在函数里面改变传递的值会影响到外面
但答案是 JavaScript 对所有数据类型都使用按值传递。它对数组和对象使用按值传递,但这是在的共享传参或拷贝的引用中使用的按值传参。这些说有些抽象,先来几个例子,接着,我们将研究JavaScript在 函数执行期间的内存模型,以了解实际发生了什么。
按值传参
在 JavaScript 中,原始类型的数据是按值传参;对象类型是跟Java一样,拷贝了原来对象的一份引用,对这个引用进行操作。但在 JS 中,string 就是一种原始类型数据而不是对象类。
let setNewInt = function (i) {
i = i + 33;
};
let setNewString = function (str) {
str += "cool!";
};
let setNewArray = function (arr1) {
var b = [1, 2];
arr1 = b;
};
let setNewArrayElement = function (arr2) {
arr2[0] = 105;
};
let i = -33;
let str = "I am ";
let arr1 = [-4, -3];
let arr2 = [-19, 84];
console.log('i is: ' + i + ', str is: ' + str + ', arr1 is: ' + arr1 + ', arr2 is: ' + arr2);
setNewInt(i);
setNewString(str);
setNewArray(arr1);
setNewArrayElement(arr2);
console.log('现在, i is: ' + i + ', str is: ' + str + ', arr1 is: ' + arr1 + ', arr2 is: ' + arr2);
运行结果
i is: -33, str is: I am , arr1 is: -4,-3, arr2 is: -19,84
现在, i is: -33, str is: I am , arr1 is: -4,-3, arr2 is: 105,84
这边需要注意的两个地方:
1)第一个是通过 setNewString 方法把字符串 str 传递进去,如果学过面向对象的语言如C#,Java 等,会认为调用这个方法后 str 的值为改变,引用这在面向对象语言中是 string 类型的是个对象,按引用传参,所以在这个方法里面更改 str外面也会跟着改变。
但是 JavaScript 中就像前面所说,在JS 中,string 就是一种原始类型数据而不是对象类,所以是按值传递,所以在 setNewString 中更改 str 的值不会影响到外面。
2)第二个是通过 setNewArray 方法把数组 arr1 传递进去,因为数组是对象类型,所以是引用传递,在这个方法里面我们更改 arr1 的指向,所以如果是这面向对象语言中,我们认为最后的结果arr1 的值是重新指向的那个,即 [1, 2],但最后打印结果可以看出 arr1 的值还是原先的值,这是为什么呢?
共享传递
Stack Overflow上Community Wiki 对上述的回答是:对于传递到函数参数的对象类型,如果直接改变了拷贝的引用的指向地址,那是不会影响到原来的那个对象;如果是通过拷贝的引用,去进行内部的值的操作,那么就会改变到原来的对象的。
可以参考博文 JavaScript Fundamentals (2) – Is JS call-by-value or call-by-reference?
function changeStuff(state1, state2)
{
state1.item = 'changed';
state2 = {item: "changed"};
}
var obj1 = {item: "unchanged"};
var obj2 = {item: "unchanged"};
changeStuff(obj1, obj2);
console.log(obj1.item); // obj1.item 会被改变
console.log(obj2.item); // obj2.item 不会被改变
缘由: 上述的 state1 相当于 obj1, 然后 obj1.item = 'changed',对象 obj1 内部的 item 属性进行了改变,自然就影响到原对象 obj1 。类似的,state2 也是就 obj2,在方法里 state2 指向了一个新的对象,也就是改变原有引用地址,这是不会影响到外面的对象(obj2),这种现象更专业的叫法:call-by-sharing,这边为了方便,暂且叫做 共享传递。
内存模型
JavaScript 在执行期间为程序分配了三部分内存:代码区,调用堆栈和堆。 这些组合在一起称为程序的地址空间。
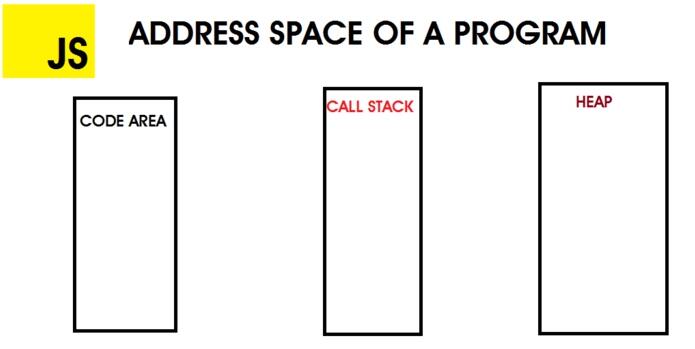
代码区:这是存储要执行的JS代码的区域。
调用堆::这个区域跟踪当前正在执行的函数,执行计算并存储局部变量。变量以后进先出法存储在堆栈中。最后一个进来的是第一个出去的,数值数据类型存储在这里。
例如:
var corn = 95
let lion = 100
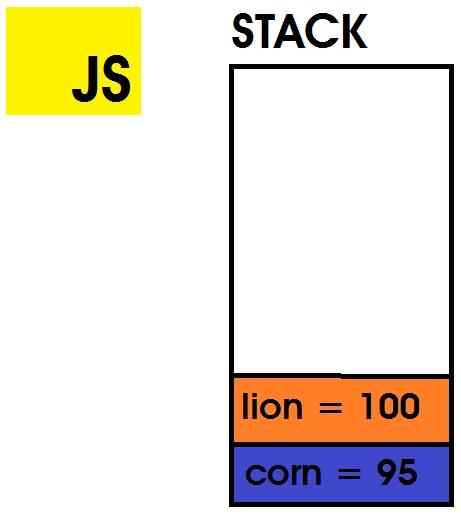
在这里,变量 corn 和 lion 值在执行期间存储在堆栈中。
堆:是分配 JavaScript 引用数据类型(如对象)的地方。 与堆栈不同,内存分配是随机放置的,没有 LIFO策略。 为了防止堆中的内存漏洞,JS引擎有防止它们发生的内存管理器。
class Animal {}
// 在内存地址 0x001232 上存储 new Animal() 实例
// tiger 的堆栈值为 0x001232
const tiger = new Animal()
// 在内存地址 0x000001 上存储 new Objec实例
// `lion` 的堆栈值为 0x000001
let lion = {
strength: "Very Strong"
}
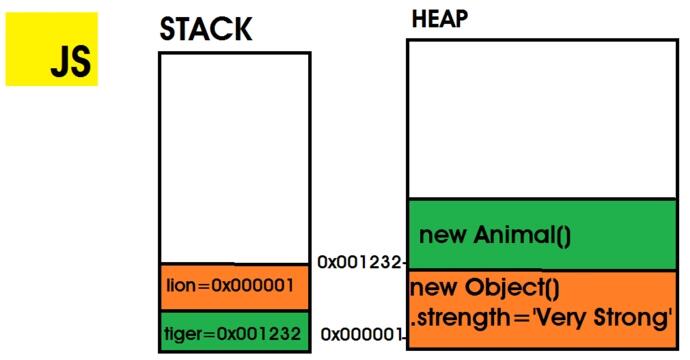
Here,lion 和 tiger 是引用类型,它们的值存储在堆中,并被推入堆栈。它们在堆栈中的值是堆中位置的内存地址。
激活记录(Activation Record),参数传递
我们已经看到了 JS 程序的内存模型,现在,让我们看看在 JavaScript 中调用函数时会发生什么。
// 例子一
function sum(num1,num2) {
var result = num1 + num2
return result
}
var a = 90
var b = 100
sum(a, b)
每当在 JS 中调用一个函数时,执行该函数所需的所有信息都放在堆栈上。这个信息就是所谓的激活记录(Activation Record)。
这个 Activation Record,我直译为激活记录,找了好多资料,没有看到中文一个比较好的翻译,如果朋友们知道,欢迎留言。
激活记录上的信息包括以下内容:
- SP 堆栈指针:调用方法之前堆栈指针的当前位置。
- RA 返回地址:这是函数执行完成后继续执行的地址。
- RV 返回值:这是可选的,函数可以返回值,也可以不返回值。
- 参数:将函数所需的参数推入堆栈。
- 局部变量:函数使用的变量被推送到堆栈。
我们必须知道这一点,我们在js文件中编写的代码在执行之前由 JS 引擎(例如 V8,Rhino,SpiderMonke y等)编译为机器语言。
所以以下的代码:
let shark = "Sea Animal"
会被编译成如下机器码:
01000100101010
01010101010101
上面的代码是我们的js代码等价。 机器码和 JS 之间有一种语言,它是汇编语言。 JS 引擎中的代码生成器在最终生成机器码之前,首先是将 js 代码编译为汇编代码。
为了了解实际发生了什么,以及在函数调用期间如何将激活记录推入堆栈,我们必须了解程序是如何用汇编表示的。
为了跟踪函数调用期间参数是如何在 JS 中传递的,我们将例子一的代码使用汇编语言表示并跟踪其执行流程。
先介绍几个概念:
ESP:(Extended Stack Pointer)为扩展栈指针寄存器,是指针寄存器的一种,用于存放函数栈顶指针。与之对应的是 EBP(Extended Base Pointer),扩展基址指针寄存器,也被称为帧指针寄存器,用于存放函数栈底指针。
EBP:扩展基址指针寄存器(extended base pointer) 其内存放一个指针,该指针指向系统栈最上面一个栈帧的底部。
EBP 只是存取某时刻的 ESP,这个时刻就是进入一个函数内后,cpu 会将ESP的值赋给 EBP,此时就可以通过 EBP 对栈进行操作,比如获取函数参数,局部变量等,实际上使用 ESP 也可以。
// 例子一
function sum(num1,num2) {
var result = num1 + num2
return result
}
var a = 90
var b = 100
var s = sum(a, b)
我们看到 sum 函数有两个参数 num1 和 num2。函数被调用,传入值分别为 90 和 100 的 a 和 b。
记住:值数据类型包含值,而引用数据类型包含内存地址。
在调用 sum 函数之前,将其参数推入堆栈
ESP->[......]
ESP->[ 100 ]
[ 90 ]
[.......]
然后,它将返回地址推送到堆栈。返回地址存储在EIP 寄存器中:
ESP->[Old EIP]
[ 100 ]
[ 90 ]
[.......]
接下来,它保存基指针
ESP->[Old EBP]
[Old EIP]
[ 100 ]
[ 90 ]
[.......]
然后更改 EBP 并将调用保存寄存器推入堆栈。
ESP->[Old ESI]
[Old EBX]
[Old EDI]
EBP->[Old EBP]
[Old EIP]
[ 100 ]
[ 90 ]
[.......]
为局部变量分配空间:
ESP->[ ]
[Old ESI]
[Old EBX]
[Old EDI]
EBP->[Old EBP]
[Old EIP]
[ 100 ]
[ 90 ]
[.......]
这里执行加法:
mov ebp+4, eax ; 100
add ebp+8, eax ; eax = eax + (ebp+8)
mov eax, ebp+16
ESP->[ 190 ]
[Old ESI]
[Old EBX]
[Old EDI]
EBP->[Old EBP]
[Old EIP]
[ 100 ]
[ 90 ]
[.......]
我们的返回值是190,把它赋给了 EAX。
mov ebp+16, eax
EAX 是"累加器"(accumulator), 它是很多加法乘法指令的缺省寄存器。
然后,恢复所有寄存器值。
[ 190 ] DELETED
[Old ESI] DELETED
[Old EBX] DELETED
[Old EDI] DELETED
[Old EBP] DELETED
[Old EIP] DELETED
ESP->[ 100 ]
[ 90 ]
EBP->[.......]
并将控制权返回给调用函数,推送到堆栈的参数被清除。
[ 190 ] DELETED
[Old ESI] DELETED
[Old EBX] DELETED
[Old EDI] DELETED
[Old EBP] DELETED
[Old EIP] DELETED
[ 100 ] DELETED
[ 90 ] DELETED
[ESP, EBP]->[.......]
调用函数现在从 EAX 寄存器检索返回值到 s 的内存位置。
mov eax, 0x000002 ; // s 变量在内存中的位置
我们已经看到了内存中发生了什么以及如何将参数传递汇编代码的函数。
调用函数之前,调用者将参数推入堆栈。因此,可以正确地说在 js 中传递参数是传入值的一份拷贝。如果被调用函数更改了参数的值,它不会影响原始值,因为它存储在其他地方,它只处理一个副本。
function sum(num1) {
num1 = 30
}
let n = 90
sum(n)
// `n` 仍然为 90
让我们看看传递引用数据类型时会发生什么。
function sum(num1) {
num1 = { number:30 }
}
let n = { number:90 }
sum(n)
// `n` 仍然是 { number:90 }
用汇编代码表示:
n -> 0x002233
Heap: Stack:
002254 012222
... 012223 0x002233
002240 012224
002239 012225
002238
002237
002236
002235
002234
002233 { number: 90 }
002232
002231 { number: 30 }
Code:
...
000233 main: // entry point
000234 push n // n 值为 002233 ,它指向堆中存放 {number: 90} 地址。 n 被推到堆栈的 0x12223 处.
000235 ; // 保存所有寄存器
...
000239 call sum ; // 跳转到内存中的`sum`函数
000240
...
000270 sum:
000271 ; // 创建对象 {number: 30} 内在地址主 0x002231
000271 mov 0x002231, (ebp+4) ; // 将内存地址为 0x002231 中 {number: 30} 移动到堆栈 (ebp+4)。(ebp+4)是地址 0x12223 ,即 n 所在地址也是对象 {number: 90} 在堆中的位置。这里,堆栈位置被值 0x002231 覆盖。现在,num1 指向另一个内存地址。
000272 ; // 清理堆栈
...
000275 ret ; // 回到调用者所在的位置(000240)
我们在这里看到变量n保存了指向堆中其值的内存地址。 在sum 函数执行时,参数被推送到堆栈,由 sum 函数接收。
sum 函数创建另一个对象 {number:30},它存储在另一个内存地址 002231 中,并将其放在堆栈的参数位置。 将前面堆栈上的参数位置的对象 {number:90} 的内存地址替换为新创建的对象 {number:30} 的内存地址。
这使得 n 保持不变。因此,复制引用策略是正确的。变量 n 被推入堆栈,从而在 sum 执行时成为 n 的副本。
此语句 num1 = {number:30} 在堆中创建了一个新对象,并将新对象的内存地址分配给参数 num1。 注意,在 num1 指向 n 之前,让我们进行测试以验证:
// example1.js
let n = { number: 90 }
function sum(num1) {
log(num1 === n)
num1 = { number: 30 }
log(num1 === n)
}
sum(n)
$ node example1
true
false
是的,我们是对的。就像我们在汇编代码中看到的那样。最初,num1 引用与 n 相同的内存地址,因为n被推入堆栈。
然后在创建对象之后,将 num1 重新分配到对象实例的内存地址。
让我们进一步修改我们的例子1:
function sum(num1) {
num1.number = 30
}
let n = { number: 90 }
sum(n)
// n 成为了 { number: 30 }
这将具有与前一个几乎相同的内存模型和汇编语言。这里只有几件事不太一样。在 sum 函数实现中,没有新的对象创建,该参数受到直接影响。
...
000270 sum:
000271 mov (ebp+4), eax ; // 将参数值复制到 eax 寄存器。eax 现在为 0x002233
000271 mov 30, [eax]; // 将 30 移动到 eax 指向的地址
num1 是(ebp+4),包含 n 的地址。值被复制到 eax 中,30 被复制到 eax 指向的内存中。任何寄存器上的花括号 [] 都告诉 CPU 不要使用寄存器中找到的值,而是获取与其值对应的内存地址号的值。因此,检索 0x002233 的 {number: 90}值。
看看这样的答案:
原始数据类型按值传递,对象通过引用的副本传递。
具体来说,当你传递一个对象(或数组)时,你无形地传递对该对象的引用,并且可以修改该对象的内容,但是如果你尝试覆盖该引用,它将不会影响该对象的副本- 即引用本身按值传递:
function replace(ref) {
ref = {}; // 这段代码不影响传递的对象
}
function update(ref) {
ref.key = 'newvalue'; // 这段代码确实会影响对象的内容
}
var a = { key: 'value' };
replace(a); // a 仍然有其原始值,它没有被修改的
update(a); // a 的内容被更改
从我们在汇编代码和内存模型中看到的。这个答案百分之百正确。在 replace 函数内部,它在堆中创建一个新对象,并将其分配给 ref 参数,a 对象内存地址被重写。
update 函数引用 ref 参数中的内存地址,并更改存储在存储器地址中的对象的key属性。
总结
根据我们上面看到的,我们可以说原始数据类型和引用数据类型的副本作为参数传递给函数。不同之处在于,在原始数据类型,它们只被它们的实际值引用。JS不允许我们获取他们的内存地址,不像在C与C++程序设计学习与实验系统,引用数据类型指的是它们的内存地址。
原文:https://blog.bitsrc.io/master-javascript-call-by-sharing-parameter-passing-7049d65163ed
本文内容仅供个人学习、研究或参考使用,不构成任何形式的决策建议、专业指导或法律依据。未经授权,禁止任何单位或个人以商业售卖、虚假宣传、侵权传播等非学习研究目的使用本文内容。如需分享或转载,请保留原文来源信息,不得篡改、删减内容或侵犯相关权益。感谢您的理解与支持!

